
DeepSeek V3 est une version historique majeure de la famille DeepSeek. Elle reste utile pour comprendre l’évolution de la gamme, mais si vous cherchez le modèle officiellement mis en avant aujourd’hui, consultez d’abord DeepSeek‑V3.2 et les annonces officielles les plus récentes.
Développé initialement par une start-up chinoise en 2023 (soutenue par High-Flyer Capital) et ouvert à la communauté, ce modèle d’intelligence artificielle conversationnelle vise à démocratiser l’accès aux capacités des LLM avancés.
DeepSeek V3 est particulièrement optimisé pour le français, offrant une compréhension fine des nuances de la langue et une génération de texte fluide et cohérente, là où d’autres modèles majoritairement entraînés en anglais peuvent montrer leurs limites.
Grâce à sa puissance et à son entraînement multilingue, il peut comprendre et répondre en français avec une précision contextuelle remarquable, tout en restant polyvalent sur de nombreuses tâches en NLP (Natural Language Processing).
En résumé, DeepSeek V3 se présente comme un modèle conversationnel de pointe, gratuit et open-source, offrant des performances comparables aux meilleurs modèles fermés du marché (il rivalise par exemple avec GPT-4 sur des tâches complexes).
Les développeurs IA y trouvent non seulement un outil performant, mais aussi une plateforme transparente qu’ils peuvent auditer, déployer et personnaliser selon leurs besoins.
Dans cet article, nous allons explorer en détail les capacités générales de DeepSeek V3, son architecture technique innovante, ainsi que des cas d’usage concrets illustrant comment ce modèle peut s’intégrer dans vos projets de développement en IA.
Architecture du modèle DeepSeek V3
DeepSeek V3 s’appuie sur une architecture Transformer optimisée et innovante pour allier échelle massive et efficacité.
Son cœur technologique repose sur le principe du Mixture-of-Experts (MoE) – en français « mélange d’experts » – c’est-à-dire qu’il intègre de multiples sous-modèles (des “experts”) spécialisés, parmi lesquels seuls les plus pertinents sont activés pour traiter une requête donnée.
En pratique, le modèle comporte 671 milliards de paramètres au total, mais grâce à cette approche sparse, seulement environ 37 milliards de paramètres sont activés pour chaque token généré. Cette conception permet à DeepSeek V3 de bénéficier d’une capacité de modèle gigantesque tout en maintenant des coûts de calcul raisonnables à l’inférence.
Autrement dit, on obtient la qualité d’un très grand modèle avec le budget de calcul d’un modèle plus petit. DeepSeek V3 brille ainsi par la richesse de ses réponses tout en étant très rapide en génération.
Innovations techniques internes
Plusieurs choix de design distinguent l’architecture de DeepSeek V3 des LLM traditionnels :
- Multi-Head Latent Attention (MLA) : une variante optimisée du mécanisme d’attention, qui compresse les clés/valeurs et requêtes de l’attention multi-tête. Cette compression réduit drastiquement la mémoire nécessaire pour stocker le contexte (les KV cache) sans perte de performance par rapport à une attention standard. Concrètement, cela signifie que DeepSeek V3 peut gérer des contextes bien plus longs qu’un modèle classique sans explosion de la mémoire. Le modèle supporte ainsi une fenêtre de contexte étendue jusqu’à 128 000 tokens (soit des dizaines de milliers de mots) pour les entrées, contre quelques milliers habituellement. Cette capacité hors-norme lui permet de conserver le fil de conversations très longues ou d’analyser de vastes documents en une seule passe.
- Mixture-of-Experts évolué : DeepSeek V3 pousse le concept de MoE encore plus loin en augmentant le nombre d’« experts » internes par rapport aux itérations précédentes. Il dispose de plus de 250 experts répartis sur ses couches et peut en activer en moyenne 9 par token généré. De plus, une stratégie de routage équilibré locale a été implémentée pour éviter le piège du routing collapse (où quelques experts accapareraient toutes les requêtes). Contrairement à la version antérieure qui utilisait des pertes auxiliaires pour forcer l’équilibrage, V3 adopte une approche sans perte auxiliaire, en injectant plutôt un léger biais dans le mécanisme de gating pour encourager une meilleure répartition des requêtes entre experts. Cette élimination des pertes auxiliaires permet d’améliorer la qualité globale du modèle : même si l’utilisation des experts est moins équilibrée, chaque token est routé vers l’expert le plus qualifié sans compromis artificiel, ce qui aboutit à de meilleures performances finales.
- Entraînement en précision FP8 : DeepSeek V3 est le premier LLM open-source à avoir été pré-entraîné en utilisant la précision FP8 (8 bits flottants) sur l’ensemble de son architecture. Cette prouesse technique, validée sur un modèle de cette échelle, offre deux avantages majeurs : (1) Doubler la vitesse de calcul pour les multiplications de matrices par rapport au FP16/BF16 classique, grâce à l’exploitation optimisée des Tensor Cores NVIDIA; (2) Réduire de moitié l’utilisation mémoire lors de l’entraînement, ce qui a permis d’entraîner un modèle plus grand sur le même matériel. En outre, l’équipe a co-conçu l’algorithme, le framework et l’infrastructure hardware pour overlap au maximum calcul et communication dans le cas de l’entraînement MoE distribué, éliminant les goulets d’étranglement réseau. Résultat : malgré sa taille colossale, DeepSeek V3 a été pré-entraîné sur plus de 14 800 milliards de tokens (14.8 trillion de données textuelles variées) en seulement ~2,66 millions d’heures GPU H800 – un exploit d’efficacité quand on le compare aux budgets de calcul de modèles similaires. L’entraînement s’est par ailleurs avéré remarquablement stable, sans spikes de perte irréversibles ni besoin de reprise à partir de checkpoints anciens sur l’ensemble du processus.
- Objectif de prédiction multi-tokens : En complément de la traditionnelle prédiction token par token, DeepSeek V3 introduit un objectif d’entraînement novateur appelé Multi-Token Prediction (MTP). Cette approche incite le modèle à prédire plusieurs tokens à la fois durant l’apprentissage, ce qui enrichit ses représentations et accélère potentiellement l’inférence via des techniques de speculative decoding. En synthèse, le modèle apprend non seulement à anticiper le prochain mot, mais également les suivants, renforçant ainsi sa cohérence sur des séquences plus longues. Ceci contribue à améliorer les performances globales sur de nombreux benchmarks tout en ouvrant la voie à des générations plus rapides.
Enfin, il convient de mentionner que DeepSeek V3 a suivi après pré-entraînement des étapes de post-entraînement avancées. Notamment, une fine-tuning supervisé puis un affinage par apprentissage par renforcement (du type RLHF) ont été réalisés pour aligner le modèle aux instructions et aux préférences humaines.
De plus, l’équipe a appliqué une distillation de connaissances en transférant les capacités de raisonnement d’un modèle spécialisé (série DeepSeek R1, orienté chain-of-thought) vers V3.
Grâce à ce procédé, DeepSeek V3 a hérité de puissantes facultés de raisonnement étape-par-étape (auto-vérification des réponses, réflexion intermédiaire, etc.) sans sacrifier son style de réponse ni la maîtrise de sa longueur de sortie. L’architecture de DeepSeek V3 combine ainsi échelle, modularité et optimisations d’entraînement pour fournir une base technique solide apte à exceller sur un large éventail de tâches.
Capacités et performances générales du modèle
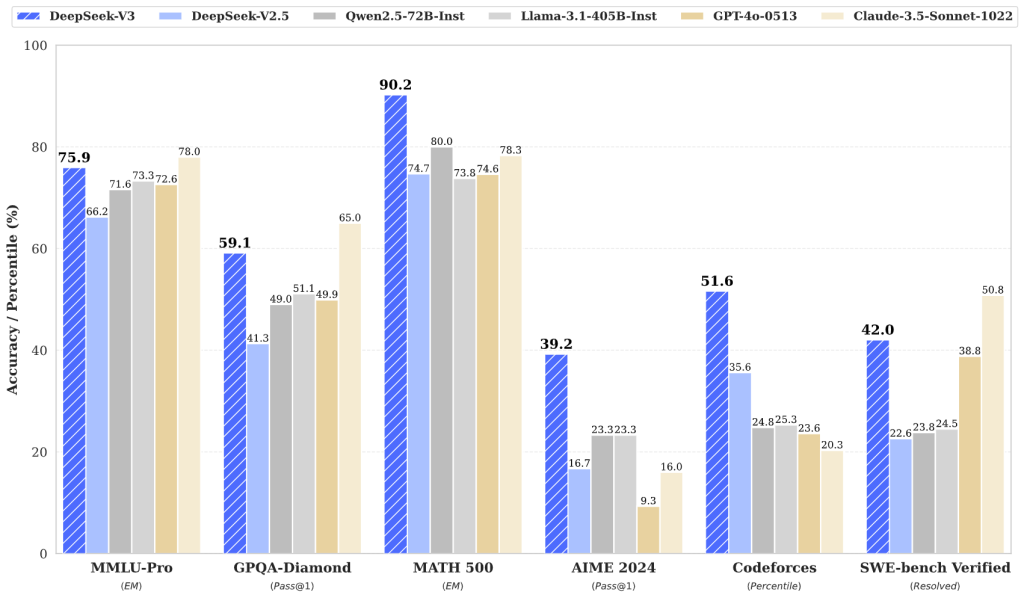
Grâce à son architecture et à son entraînement titanesques, DeepSeek V3 affiche des capacités impressionnantes qui le placent parmi les meilleurs modèles de langage actuels.
Voici un aperçu de ses performances et atouts clés :
- Excellence multilingue et compréhension du français : Formé sur un corpus colossal englobant de multiples langues, DeepSeek V3 est capable de traiter des requêtes et de générer du texte dans un grand nombre d’idiomes. Il maîtrise notamment très bien le français, offrant des réponses nuancées et culturellement pertinentes pour les utilisateurs francophones. Contrairement à certains LLM dont le français n’est qu’une langue parmi d’autres, DeepSeek a été optimisé pour cette langue et cela se reflète dans la qualité de ses réponses. Bien sûr, le modèle reste polyglotte : on peut tout autant l’interroger en anglais, en espagnol, en arabe, etc., il répondra dans la langue demandée. Il gère même la traduction automatique d’une langue à l’autre de façon fluid. Cette polyvalence linguistique en fait un outil précieux pour développer des applications globales ou localisées dans la langue de Molière.
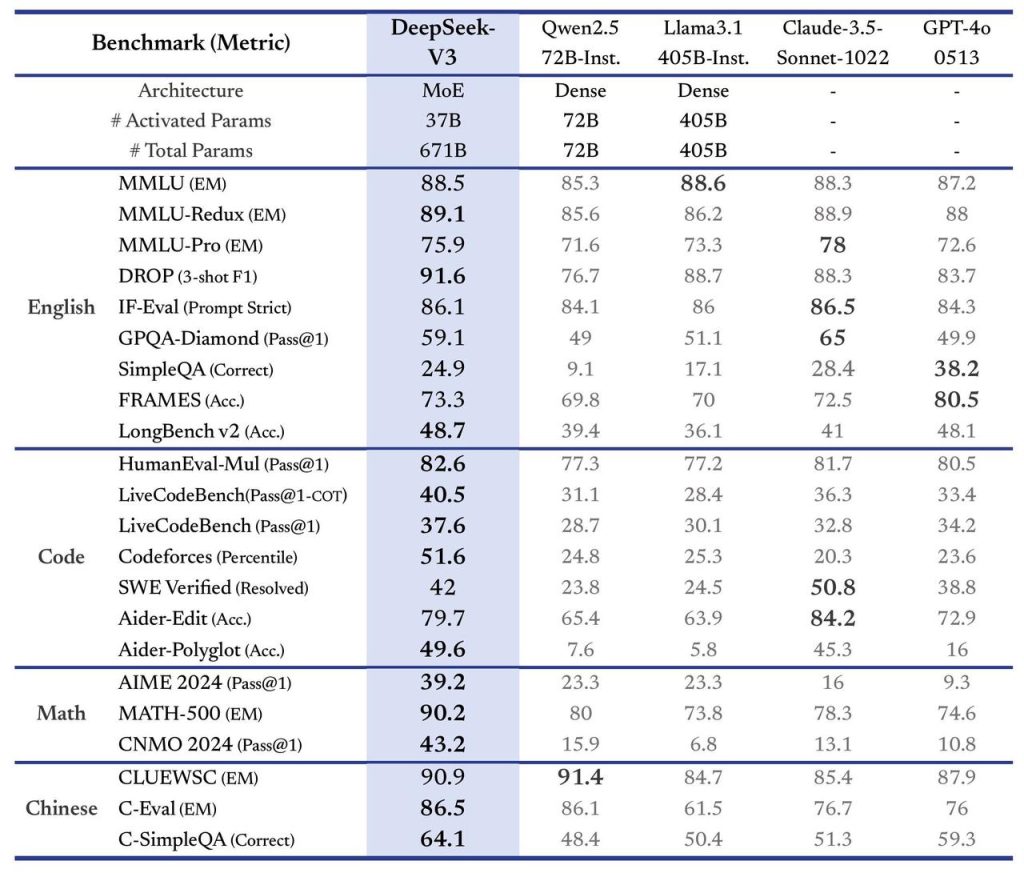
- Connaissances générales et raisonnement : DeepSeek V3 démontre une compréhension approfondie d’un large spectre de domaines, du fait de son pré-entraînement sur des données très diversifiées. Sur les benchmarks d’évaluation de connaissances académiques (tels que MMLU), il obtient des scores record (88,5 sur MMLU par exemple) surpassant tous les autres modèles open-source de sa génération. Son niveau se rapproche ainsi des modèles fermés de référence comme GPT-4 ou Claude 3.5, comblant peu à peu l’écart entre l’open-source et les solutions propriétaires haut de gamme. Surtout, il excelle en raisonnement complexe : ses capacités d’enchaînement logique et de Chain-of-Thought lui permettent de résoudre des problèmes ardus en plusieurs étapes (mathématiques, puzzles logiques, etc.). Pour les tâches nécessitant analyse et réflexion, DeepSeek V3 se hisse parmi les meilleurs, y compris face à des modèles entraînés spécifiquement pour le raisonnement.
- Performances en codage et en mathématiques : L’un des points forts de DeepSeek V3 est sa compétence en génération de code et en résolution de problèmes mathématiques. Ayant été entraîné sur d’abondantes données de code et enrichi par un modèle dérivé dédié (DeepSeek Coder), il sait écrire du code dans de nombreux langages (Python, Java, JavaScript, C++, etc.), commenter des fonctions, expliquer des algorithmes et même déboguer du code existant. Sur les benchmarks de programmation, DeepSeek V3 atteint ou dépasse l’état de l’art : par exemple, il se classe n°1 sur LiveCodeBench, un benchmark de génération de code en compétition, surpassant tous les autres modèles testés. De même, en mathématiques, il fait jeu égal voire mieux que les meilleurs modèles généralistes – surpassant même un modèle d’OpenAI (o1-preview) sur un test avancé comme MATH-500. Ces résultats témoignent de sa capacité à non seulement comprendre le langage naturel, mais aussi à raisonner sur des tâches techniques avec une grande fiabilité.
- Longue mémoire contextuelle : Comme évoqué plus haut, DeepSeek V3 peut gérer des conversations ou documents de très grande taille grâce à son contexte de 128K tokens. Cela lui confère un net avantage pour les tâches de compréhension de documents longs, la synthèse de rapports volumineux, ou le suivi de dialogues étendus. Là où la plupart des modèles perdent le fil au-delà de quelques pages de texte, DeepSeek V3 peut ingérer l’équivalent d’un livre entier en entrée. Des tests internes montrent qu’il maintient d’excellentes performances de question-réponse même en présence d’un très grand contexte, grâce notamment à son mécanisme de context caching efficace. Pour le développeur, cela signifie la possibilité de bâtir des applications d’analyse de corpus ou de conversations longues sans diviser artificiellement les données.
- Ouverture, coût et déploiement : Enfin, un atout non technique mais crucial de DeepSeek V3 est son statut open-source (licence MIT pour le code) et son accessibilité gratuite. Les poids du modèle ainsi que des rapports techniques détaillés ont été publiés librement, ce qui permet aux chercheurs et ingénieurs de l’utiliser, de l’auditer et de le modifier à volonté. Contrairement à GPT-4 ou d’autres IA fermées, DeepSeek ne requiert aucun abonnement payant pour accéder à ses fonctionnalités avancées – il est gratuit pour tous les usages (y compris commerciaux). De plus, il a été conçu pour pouvoir tourner dans divers environnements : via l’API DeepSeek officielle pour une intégration facile, en déploiement local/on-premise pour les entreprises ayant des contraintes de confidentialité, ou même sur des GPUs variés (NVIDIA, AMD, Huawei Ascend) grâce aux efforts de compatibilité réalisés. Cette flexibilité de déploiement garantit que les développeurs peuvent intégrer DeepSeek V3 dans leurs pipelines avec un contrôle total sur les données et les coûts, ce qui en fait une solution pragmatique en plus d’être performante.
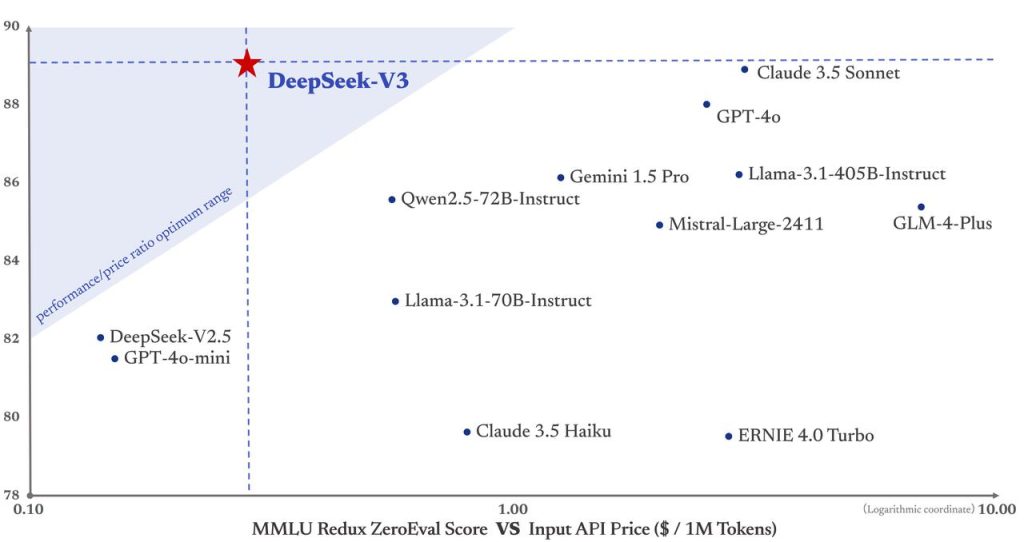
En somme, DeepSeek V3 se démarque par son écosystème complet de capacités : compréhension fine du langage naturel (en français notamment), génération de texte de haute qualité, compétences techniques en code et en calcul, mémoire contextuelle étendue, le tout dans un cadre ouvert et maîtrisable. Cela ouvre la porte à de nombreux cas d’usage dans le développement logiciel et l’IA.
Cas d’usage de DeepSeek V3 dans des projets IA
Quelles opportunités concrètes offre DeepSeek V3 pour les développeurs d’IA ? Grâce à sa polyvalence, ce modèle peut être exploité dans un grand nombre de scénarios applicatifs. Voici quelques cas d’usage illustrant comment DeepSeek V3 peut s’intégrer dans vos projets et produits :
Assistant virtuel et chatbot conversationnel
DeepSeek V3 peut servir de moteur IA conversationnel au cœur d’un chatbot avancé. Par exemple, vous pouvez l’intégrer via son API dans un système de service client pour gérer automatiquement les demandes des utilisateurs 24h/24 et 7j/7.
Il sera capable de répondre aux questions fréquentes, de guider les usagers dans vos services et même de traiter des requêtes plus complexes en langage naturel.
Sa maîtrise du français assure une interaction fluide et naturelle avec votre clientèle. De plus, comme DeepSeek est open-source, il est possible de le entraîner ou affiner sur vos données spécifiques (documents internes, FAQ métier, etc.) afin de personnaliser ses réponses à votre domaine (finance, santé, e-commerce…).
Ainsi, les entreprises peuvent déployer des chatbots spécialisés combinant la puissance générale de V3 et la connaissance pointue de leur secteur – le tout sans dépendre d’une solution propriétaire.
Génération de contenu et NLP avancé
En tant que modèle de langage de pointe, DeepSeek V3 excelle dans toutes les tâches classiques de NLP. Il peut automatiquement rédiger des textes variés : descriptions de produits, comptes-rendus, articles de blog, emails professionnels, histoires courtes, etc.
Par exemple, on peut lui demander « Rédige un résumé des points clés d’un rapport technique de 50 pages » et obtenir en quelques secondes un texte synthétique et bien structuré.
De même, il réalise des traductions de haute qualité d’une langue à l’autre ou des reformulations de phrases pour améliorer un texte. Les développeurs peuvent donc l’utiliser pour des applications de traduction automatique, de rédaction assistée (génération de brouillons, de réponses email, etc.), ou encore de révision linguistique (correction et amélioration de textes).
Son aptitude à comprendre le contexte sur de longs passages le rend particulièrement efficace pour résumer de longs documents ou extraire l’information pertinente au sein de données textuelles volumineuses. En somme, DeepSeek V3 offre un véritable outil de productivité linguistique pour tout projet nécessitant de manipuler du langage naturel de façon intelligente.
Agent intelligent et automatisation de tâches
Combiné à des frameworks d’orchestration (par ex. LangChain, Transformers Agents…), DeepSeek V3 peut devenir le cerveau d’agents autonomes capables d’exécuter des tâches complexes.
Ses capacités de raisonnement par chain-of-thought, renforcées par la distillation de DeepSeek R1, lui permettent de planifier des étapes, de faire des appels d’API ou d’interagir avec un environnement externe de manière réfléchie.
Un développeur peut l’utiliser pour construire un assistant IA multi-outils : par exemple un agent qui consulte une base de connaissances interne pour répondre à des questions pointues, qui réalise des calculs sur demande, ou qui envoie des emails automatiquement selon des instructions en langage naturel.
Grâce à son long contexte, l’agent peut conserver en mémoire l’historique des interactions ou un état de travail conséquent. DeepSeek V3 devient ainsi une composante clé pour bâtir des systèmes d’IA proactifs (assistants personnels, bots de recherche d’information, automatisation de support IT, etc.) qui requièrent compréhension, raisonnement multi-étapes et action. En outre, le fait de pouvoir l’auto-héberger offre un niveau de contrôle et de confidentialité précieux dans ces scénarios sensibles.
Assistante de programmation (IA pair programmer)
Pour les développeurs logiciels, DeepSeek V3 peut jouer le rôle d’un assistant de codage très performant. Via l’intégration d’un module dédié (DeepSeek Coder) ou directement le modèle de base, il est possible de l’utiliser dans un IDE ou une application pour épauler les programmeurs.
Par exemple, on peut lui soumettre un extrait de code en lui demandant « Explique-moi ce que fait ce code et pourquoi il ne fonctionne pas », et l’IA fournira une analyse pas à pas, en pointant d’éventuelles erreurs logique. On peut également lui demander « Écris une fonction qui trie une liste de produits par prix en SQL » : DeepSeek va alors générer le code correspondant, correctement structuré et commenté.
Il excelle aussi à suggérer des améliorations de performances ou des corrections de bugs. Cet usage de DeepSeek V3 comme “pair programmer virtuel” booste la productivité des développeurs, qu’ils soient débutants (en fournissant des explications pédagogiques) ou expérimentés (en automatisant des tâches répétitives de codage).
En outre, contrairement à des solutions de code assisté propriétaires, une instance locale de DeepSeek garantit la confidentialité du code source de votre entreprise tout en évitant les coûts liés à l’utilisation d’une API payante tierce.
Analyse de données et applications verticales
Au-delà des cas génériques, DeepSeek V3 peut être adapté à de nombreux domaines sectoriels. Grâce à des modèles spécialisés de la suite DeepSeek (tels que DeepSeek Math pour les mathématiques ou bientôt DeepSeek Janus pour la vision multimodale), on peut imaginer des solutions IA ciblées.
Par exemple, dans le secteur médical, DeepSeek pourrait aider à analyser des comptes-rendus cliniques et extraire des insights, ou servir de conseiller virtuel aux médecins en se basant sur la littérature scientifique. Dans la finance, il peut assister à la génération de rapports financiers, à l’évaluation de risques en langage naturel, etc.
Avec Janus (module vision en cours de développement), l’écosystème DeepSeek permettra aussi de générer des images à partir de texte ou de décrire des images, ouvrant la voie à des cas d’usage créatifs (design assisté, prototypage visuel, etc.). En réalité, chaque secteur – juridique, éducation, marketing, ressources humaines, industrie – peut tirer parti de ce modèle en l’adaptant à ses données et à ses problématiques spécifiques.
La communauté open-source enrichit continuellement les usages de DeepSeek, et de nouveaux scénarios émergent tous les jours, de la génération de poèmes personnalisés aux simulations d’entretien d’embauche. En tant que développeur, vous avez la liberté d’expérimenter avec DeepSeek V3 et d’inventer les applications IA de demain grâce à sa flexibilité.
Conclusion : Adoptez DeepSeek V3 dans vos projets IA
DeepSeek V3 représente l’un des modèles de langage les plus avancés et accessibles pour la communauté des développeurs. Son architecture sophistiquée lui confère une puissance de raisonnement et de génération comparable à l’état de l’art tout en étant économique à déployer.
Ses capacités polyvalentes – de la conversation en langue naturelle au codage, en passant par la compréhension de documents longs – en font un atout de choix pour enrichir vos applications et workflows d’IA.
Surtout, son ADN open-source garantit une transparence et une liberté d’utilisation totales : vous pouvez auditer son fonctionnement, le personnaliser, l’héberger où bon vous semble, sans contrainte autre que le respect de sa licence permissive.
Que vous souhaitiez développer un chatbot francophone ultra-performant, intégrer une IA générative dans vos outils internes, ou explorer de nouvelles frontières en intelligence artificielle, DeepSeek V3 vous offre une base fiable et robuste.
Les premiers retours d’expérience montrent qu’il est capable de transformer la façon de travailler dans divers secteurs en automatisant des tâches complexes et en accélérant l’accès à l’information.
Il est temps de passer de la théorie à la pratique : n’hésitez pas à essayer DeepSeek V3 par vous-même et à l’intégrer dans vos projets. Grâce à sa communauté active, de nombreuses ressources (guides, exemples de code, documentation API) sont disponibles pour vous aider à démarrer rapidement.
Essayez dès maintenant DeepSeek V3 sur le site officiel – vous pourrez y discuter avec le modèle en français, accéder à l’API et rejoindre la communauté qui construit l’IA open-source de demain. Embarquez avec DeepSeek et donnez vie à vos idées d’IA les plus ambitieuses !


