
DeepSeek Janus est une intelligence artificielle multimodale de pointe, capable aussi bien de comprendre des images que d’en générer à partir de texte.
Ce modèle révolutionnaire développé par l’équipe DeepSeek a récemment suscité un vif intérêt dans la communauté pour sa capacité unique à traiter de manière unifiée le texte et l’image.
Que vous soyez débutant curieux de nouvelles technologies ou professionnel de l’IA cherchant les dernières avancées, DeepSeek Janus offre une approche innovante de la vision artificielle et de la génération d’images par IA.
Dans cet article, nous allons explorer ce qu’est DeepSeek Janus, ses principales capacités, en quoi son architecture se distingue, comment il se compare à d’autres modèles célèbres (tels que DALL-E, Midjourney ou Gemini), ainsi que des exemples concrets d’utilisation et les avantages techniques qu’il apporte pour des cas d’usage créatifs ou professionnels.
Qu’est-ce que DeepSeek Janus ?
DeepSeek Janus est un modèle d’IA multimodal (texte-image) mis au point par la société DeepSeek. Concrètement, cela signifie qu’il sait gérer à la fois du texte et des images comme entrées ou sorties.
Là où la plupart des intelligences artificielles se spécialisent soit dans la vision (analyse d’images) soit dans la génération d’images, DeepSeek Janus combine ces deux facultés au sein d’un même modèle unifié.
Par exemple, il peut décrire le contenu d’une image qu’on lui fournit ou créer une image originale à partir d’une description textuelle donnée par l’utilisateur.
Le nom Janus fait référence au dieu romain à deux visages, symbole de la double compétence du modèle : d’un côté comprendre ce qu’il voit, de l’autre imaginer ce qu’on lui décrit.

Principales capacités et fonctionnalités de DeepSeek Janus
- Analyse et compréhension d’images : DeepSeek Janus peut recevoir une image en entrée et fournir une description détaillée ou répondre à des questions sur son contenu. Par exemple, il identifie les objets présents sur une photo et peut expliquer la scène en langage naturel (utile pour décrire une image à un utilisateur ou pour de la recherche d’information visuelle).
- Génération d’images à partir de texte : À partir d’une simple description textuelle (prompt), le modèle est capable de créer une image originale correspondant à la demande. Vous pouvez lui demander « un paysage futuriste au coucher du soleil » et Janus générera une image illustrant ce scénario. Ce procédé de text-to-image s’effectue en quelques secondes et ouvre de vastes possibilités créatives.
- Multimodalité unifiée et interactive : Le modèle excelle dans les tâches combinant texte et image. Il peut aisément passer de l’analyse visuelle à la création visuelle. Cette intégration fluide signifie qu’une seule IA gère le tout, ce qui permet d’imaginer un assistant virtuel pouvant à la fois commenter une image donnée et générer de nouvelles images sur commande, le tout sans changer d’outil. Une telle polyvalence était jusqu’ici rare dans le domaine de l’IA.
Une architecture IA innovante pour la vision et la génération
La prouesse technique majeure de DeepSeek Janus réside dans son architecture à double voie. Contrairement aux approches traditionnelles qui utilisaient le même encodeur visuel pour comprendre et générer des images (un peu comme demander à un seul chef de concevoir le menu et de cuisiner simultanément), Janus sépare ces deux fonctions en deux modules indépendants.
Concrètement, Janus-Pro-7B « découple » le traitement visuel en deux voies distinctes :
- Voie de compréhension : elle utilise un encodeur visuel (nommé SigLIP-L) pour extraire rapidement les informations essentielles d’une image (par exemple : « c’est un chat orange sur un canapé »). Ce module sert aux tâches de vision (description d’image, VQA – Visual Question Answering, etc.).
- Voie de génération : de l’autre côté, le modèle dispose d’un module de génération visuelle qui convertit les images en une représentation discrète grâce à un tokenizer de type VQ (Vector Quantization). Cela permet au modèle de reconstruire ou de générer des images pixel par pixel, un peu comme on assemblerait patiemment des blocs de Lego pour former une scène détaillée. Ce mécanisme est utilisé pour créer de nouvelles images à partir de descriptions textuelles.
Ces deux voies alimentent ensuite un transformer unifié – le “cerveau” du modèle – qui intègre simultanément les informations visuelles et textuelles.
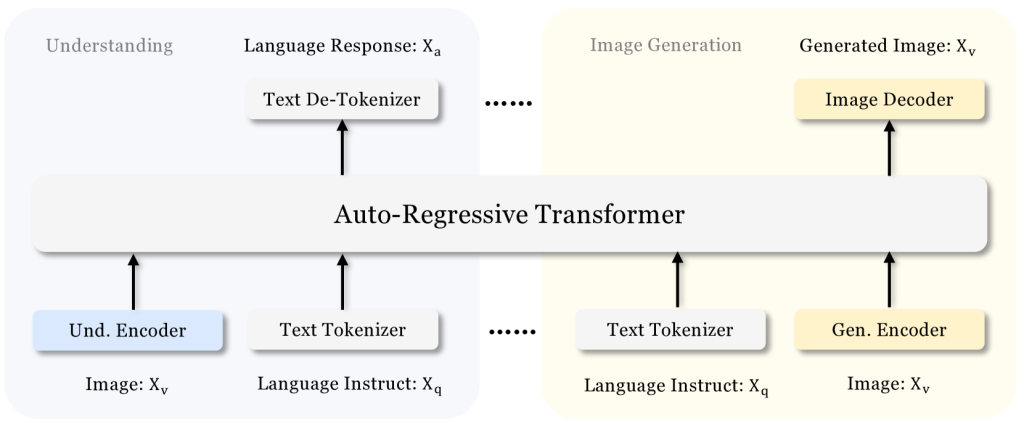
Cette conception innovante évite les conflits de rôles qui limitaient les anciens modèles et améliore la flexibilité du système ainsi que la stabilité des images générées.
En effet, chaque voie est spécialisée, ce qui permet de mieux équilibrer les compétences. De plus, l’équipe DeepSeek a entraîné Janus avec une stratégie en trois étapes sur un ensemble de données colossal, incluant environ 72 millions d’images synthétiques supplémentaires en plus des données réelles, afin d’affiner ses capacités de génération visuelle tout en conservant une excellente compréhension des images du monde réel.
Le résultat est un modèle capable de suivre précisément des instructions textuelles pour générer des images tout en interprétant finement le contenu visuel, le tout dans un seul réseau de neurones unifié.
DeepSeek Janus vs DALL-E, Midjourney, Gemini : comment se démarque-t-il ?
Plusieurs modèles d’IA se partagent déjà la scène dans le domaine de la génération d’images ou de l’IA multimodale.
Comment DeepSeek Janus se positionne-t-il face à des solutions bien connues comme DALL-E 3 d’OpenAI, Midjourney ou encore le nouveau modèle Gemini de Google ? Voici un tour d’horizon comparatif :
- DALL-E 3 (OpenAI) : DALL-E 3 est un générateur d’images à partir de texte très performant, intégré notamment à ChatGPT. Cependant, il se limite à la génération d’images et ne permet pas d’analyser une image en entrée (il ne comprend pas d’images). De plus, c’est un service propriétaire et fermé. DeepSeek Janus se distingue en étant open-source et en offrant à la fois la compréhension et la création d’images. En termes de qualité, Janus rivalise déjà avec DALL-E 3 : sur le benchmark GenEval (qui évalue la correspondance des images générées à la consigne textuelle), Janus-Pro-7B obtient environ 84 % de précision contre 83,5 % pour DALL-E 3. Certains tests rapportent même un écart plus marqué en faveur de Janus (80 % vs 67 % sur GenEval), ce qui illustre la compétitivité de ce modèle face à la référence d’OpenAI, d’autant plus remarquable qu’il est beaucoup plus léger.
- Midjourney : Midjourney est un autre générateur d’images bien connu des créatifs, produisant des visuels souvent spectaculaires à partir de prompts textuels. Comme DALL-E, il est centré uniquement sur la génération et ne traite pas d’images en entrée. Midjourney fonctionne via une plateforme fermée (accessible notamment sur Discord) et son modèle précis n’est pas public. Par rapport à Midjourney, DeepSeek Janus offre l’avantage de la polyvalence : il peut non seulement générer des images mais aussi décrire une image ou interagir avec du contenu visuel. En contrepartie, la résolution des images de Janus est pour l’instant limitée (384×384 pixels, contre des sorties souvent en haute résolution pour Midjourney) et son style visuel brut peut nécessiter un affinement ou un post-traitement pour atteindre la qualité artistique de Midjourney. Néanmoins, la possibilité de l’utiliser librement et de l’intégrer dans ses propres applications donne à Janus un atout majeur pour les développeurs et les entreprises.
- Gemini (Google) : Gemini est le nom du nouveau modèle d’IA de pointe développé par Google DeepMind, annoncé comme nativement multimodal (capable de comprendre le texte, les images, et d’autres types de données). Ce modèle, encore en déploiement progressif en 2024-2025, vise des performances générales exceptionnelles et sera proposé via les services Google (API cloud, etc.). Si Gemini promet d’exceller en vision et en génération, il reste une solution fermée et propriétaire, uniquement accessible via les produits Google. DeepSeek Janus, de son côté, offre une alternative ouverte qui, bien que plus petite en taille (7 milliards de paramètres contre des dizaines voire des centaines de milliards pour Gemini), a l’avantage d’être accessible à tous et focalisée sur le texte-image. En somme, Janus démocratise des capacités multimodales que seuls de très grands acteurs possédaient jusqu’ici, en les mettant à la portée de la communauté et des organisations de toute taille.
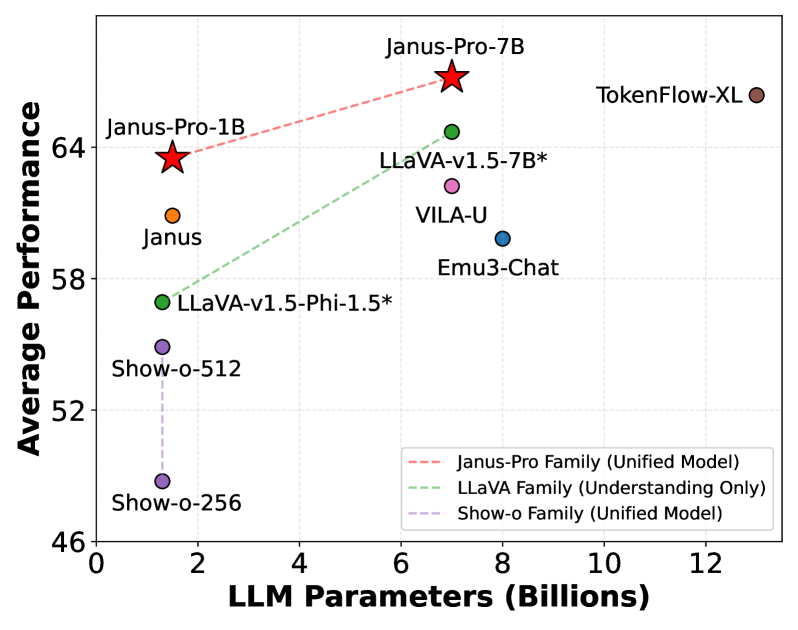
Comparaison des performances – Le graphique ci-dessus compare Janus-Pro-7B à quelques modèles concurrents sur des benchmarks évaluant la fidélité aux consignes textuelles (GenEval) et la capacité à générer des images conformes à des descriptions complexes (DPG-Bench). On observe que Janus-Pro-7B atteint l’un des meilleurs scores sur GenEval (84,2 % de précision), devançant légèrement DALL-E 3 et Stable Diffusion XL (≈83,5 % chacun), et qu’il surclasse nettement ces modèles sur le test DPG-Bench (84,1 % contre ~79 % pour DALL-E 3). Ces résultats illustrent que malgré sa taille relativement modeste, Janus-Pro-7B offre une qualité de génération d’images au niveau des meilleures IA propriétaires, tout en cumulant des fonctionnalités supplémentaires de compréhension visuelle intégrée.

Exemples concrets d’utilisation de DeepSeek Janus
- Design et industries créatives : Un graphiste peut utiliser DeepSeek Janus pour générer rapidement des prototypes visuels à partir d’idées textuelles. Par exemple, décrire « une affiche rétro-futuriste pour un festival de musique » et obtenir en quelques secondes une image conceptuelle correspondante. Les studios de jeu vidéo pourraient de même créer des ébauches de décors ou de personnages en décrivant leurs caractéristiques, accélérant ainsi la phase de prototypage visuel.
- Éducation et illustration : Des enseignants ou formateurs peuvent s’appuyer sur Janus pour illustrer dynamiquement des concepts pendant un cours. Imaginons un professeur de géographie générant en direct une image schématique d’une éruption volcanique ou d’un phénomène météorologique à partir de sa description textuelle. Cela rend les explications plus vivantes et compréhensibles pour les élèves. De plus, la capacité du modèle à expliquer des images peut servir à créer des descriptions pour l’accessibilité (par exemple décrire une image à des malvoyants).
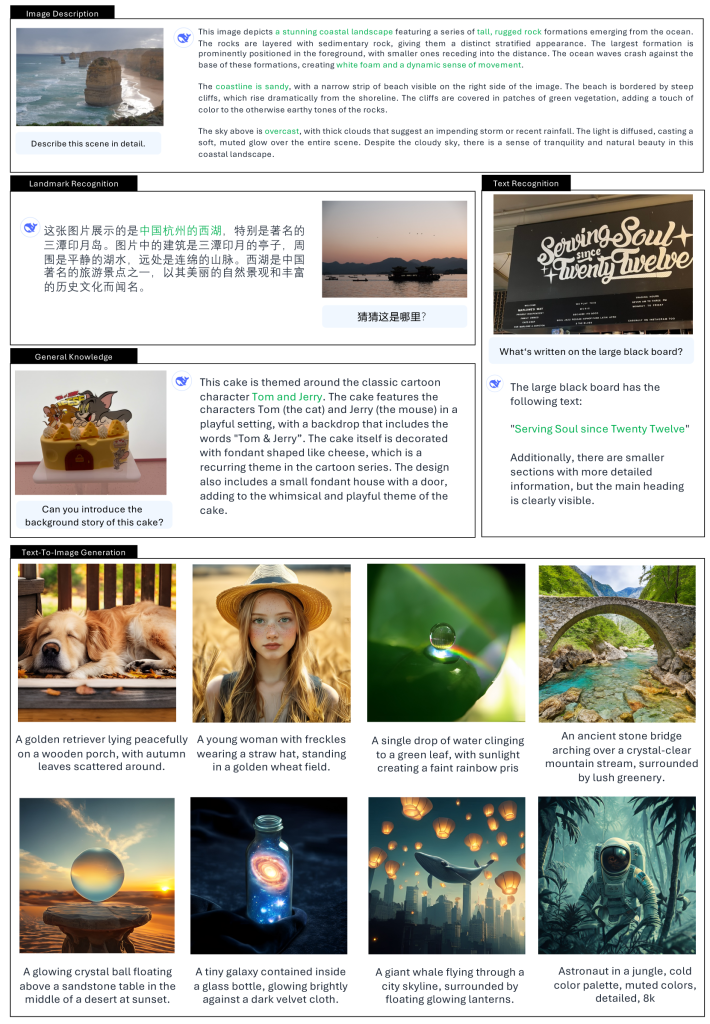
- Usage en entreprise et confidentialité : Grâce à sa disponibilité en open-source, DeepSeek Janus peut être déployé sur les serveurs internes d’une entreprise (plutôt que via un service cloud tiers). Ainsi, des secteurs manipulant des données sensibles – par exemple un hôpital analysant des images médicales ou une banque traitant des documents numérisés – peuvent exploiter les capacités de Janus sans risque de fuite de données, en gardant toutes les informations en local. Le modèle peut par exemple aider à classer automatiquement des images, à détecter des éléments visuels dans des documents, le tout avec la garantie que les données confidentielles ne quittent pas l’infrastructure de l’entreprise.
- Création artistique et culturelle : Les artistes et créateurs peuvent expérimenter avec Janus pour donner vie à des visions originales. Par exemple, en entrant un poème ou une chanson comme prompt, le modèle pourrait générer une image qui en reflète l’atmosphère. De plus, Janus possède une base de connaissances visuelles qui lui permet de reconnaître de nombreux éléments du monde réel. Il peut ainsi intégrer des références culturelles ou des lieux célèbres dans ses créations (par exemple, générer une scène se déroulant devant un monument emblématique). Cela ouvre la voie à des usages allant de la simple illustration artistique à la prévisualisation d’idées pour le cinéma, la publicité ou la valorisation du patrimoine.
Avantages techniques de DeepSeek Janus
- Open-source et libre d’utilisation : DeepSeek Janus est publié en open-source sous licence MIT, ce qui signifie que n’importe qui peut l’utiliser, l’intégrer dans ses projets, voire le modifier, y compris pour un usage commercial. C’est un contraste frappant avec des modèles comme DALL-E ou Midjourney qui sont fermés. Pour les entreprises et chercheurs, cela offre une transparence totale sur le fonctionnement du modèle et la possibilité de l’adapter à des besoins spécifiques sans contrainte de licence.
- Performance de pointe malgré sa taille réduite : Avec seulement 7 milliards de paramètres pour la version la plus avancée (Janus-Pro-7B), ce modèle parvient à atteindre des performances équivalentes ou supérieures à des modèles bien plus massifs sur des tâches multimodales. Il démontre qu’une optimisation astucieuse de l’architecture et de l’entraînement peut rivaliser avec la puissance brute. En pratique, cela se traduit par des générations d’images fidèles aux demandes et une compréhension visuelle très précise, le tout avec une empreinte beaucoup plus légère que les grands modèles propriétaires.
- Efficacité et déploiement facile : La relative compacité du modèle (1B ou 7B paramètres) permet de l’exécuter sur du matériel accessible. Par exemple, la version 7B peut tourner sur une seule carte graphique haut de gamme (~24 Go de VRAM). DeepSeek fournit même une interface simple (via Gradio) pour tester la génération d’images en quelques lignes de code ou via une démo conviviale. Cela facilite l’adoption de Janus par les développeurs, qui peuvent le déployer en local ou sur le cloud à moindre coût – une alternative économique à l’utilisation d’une API payante.
- Polyvalence et gain de temps : Au lieu de jongler entre plusieurs modèles spécialisés (un pour la vision, un pour la génération…), Janus offre une solution unifiée. Cette polyvalence simplifie les flux de travail : on peut, avec un même outil, analyser une collection d’images puis générer de nouveaux visuels à partir de ces analyses ou de nouvelles idées. Pour les équipes de création ou de développement, cela représente un gain de temps et une réduction de la complexité dans l’intégration de l’IA, puisqu’un seul système multimodal couvre un large éventail de besoins.
- Communauté et évolutivité : Étant open-source, DeepSeek Janus bénéficie du soutien d’une communauté active. Des contributeurs proposent déjà des améliorations, des fine-tunes (affinages du modèle pour des usages particuliers) ou des intégrations (par ex. des modules compatibles avec l’outil ComfyUI, etc.). Ceci garantit que le modèle pourra évoluer et s’améliorer avec le temps, grâce à l’intelligence collective, sans dépendre uniquement d’une entreprise. Cette dynamique communautaire peut conduire à des innovations supplémentaires autour de Janus, comme des versions optimisées, des extensions ou des utilisations inédites.
- Cas d’usage innovants : Les capacités uniques de Janus ouvrent la voie à des applications inédites, comme des assistants virtuels multimodaux capables de mener une conversation où ils peuvent à la fois voir et créer du contenu visuel. Dans le domaine de la recherche, il peut servir d’outil pour étudier comment un modèle apprend simultanément du texte et de l’image, ou pour concevoir de nouvelles expériences utilisateur mêlant ces deux modalités. Janus représente ainsi une plateforme d’expérimentation pour inventer de nouveaux services intelligents intégrant étroitement la vision et le langage.
- Limites actuelles : Il convient de noter quelques limites de la version actuelle. La résolution d’image de 384×384 pixels signifie que les détails très fins (texte écrit dans l’image, visages lointains, etc.) ne sont pas toujours restitués parfaitement. Pour obtenir des résultats en haute définition, on pourra recourir à des techniques d’upscaling (suréchantillonnage) après la génération, ou attendre de futures versions de Janus entraînées à des résolutions supérieures. Par ailleurs, bien que 7B paramètres soit relativement petit comparé aux grands modèles, cela nécessite tout de même une carte graphique puissante pour une utilisation fluide – le grand public ne pourra pas encore le faire tourner sur un simple PC portable. Enfin, Janus-Pro étant tout récent, il n’a pas encore bénéficié du retour d’utilisation massif qu’ont connu certains modèles commerciaux : il pourrait donc s’améliorer sur certains points à l’avenir au fil des mises à jour et itérations de son entraînement.
Conclusion
En résumé, DeepSeek Janus apporte une avancée majeure en réunissant dans un seul modèle des capacités que l’on trouvait jusque-là dispersées entre plusieurs systèmes.
Son approche multimodale ouvre de nouvelles perspectives, autant pour les utilisateurs novices – qui peuvent découvrir la génération d’images assistée par IA de manière interactive – que pour les experts, qui y voient un outil puissant et modulable.
Face aux géants propriétaires comme DALL-E 3 ou les solutions de Google, Janus trace une voie alternative axée sur l’ouverture et la collaboration communautaire.
Le fait qu’un modèle relativement léger puisse rivaliser avec les leaders du marché démontre l’importance de l’innovation architecturale et de la recherche ouverte en IA.
DeepSeek Janus, par son accessibilité et ses performances, démocratise un peu plus l’IA multimodale.
Il ne fait aucun doute que nous n’en sommes qu’au début : ce type de modèle texte-image unifié va continuer à gagner en influence dans les années à venir, transformant la façon dont nous créons et interagissons avec les contenus visuels.


