
En 2025, le paysage de l’intelligence artificielle (IA) est dominé par quelques acteurs majeurs – OpenAI (avec GPT-4 et ses successeurs), Google (avec Gemini), Anthropic (avec Claude), Meta (avec la série LLaMA), ou encore la start-up française Mistral.
Désormais, il faut y ajouter DeepSeek, une jeune entreprise chinoise dont le modèle open source de nouvelle génération défie les géants.
Cet article propose une comparaison IA objective et accessible, en examinant les performances techniques (ex : résultats aux benchmarks MMLU, HumanEval, GSM8K), les caractéristiques d’architecture (taille de contexte, multilinguisme, raisonnement) et les évolutions récentes (Claude 3.5, GPT-4o, Gemini 1.5, “Mixtral”…).
Où se situe DeepSeek parmi les meilleurs modèles IA de 2025 et quelles sont ses forces spécifiques face aux leaders ? Éléments de réponse dans ce classement des modèles IA nouvelle génération.
Panorama des modèles de langage en 2025
OpenAI reste un leader historique avec GPT-4, introduit en 2023, qui a établi des records sur de nombreux tests. GPT-4 a été suivi par des itérations améliorées comme GPT-4o (une version optimisée apparue fin 2024) et même GPT-4.5 en 2025.
Ces modèles propriétaires d’OpenAI excellent en compréhension générale, code, mathématiques et sont largement utilisés dans les entreprises.
Anthropic, de son côté, propose les modèles Claude, axés sur la fiabilité et la sécurité. Après Claude 2 (2023), Anthropic a déployé Claude 3 puis Claude 3.5 (version Sonnet) mi-2024, qui a fortement amélioré la vitesse et le raisonnement.
Anthropic affirme d’ailleurs que Claude 3.5 Sonnet surpasse non seulement son prédécesseur, mais aussi les modèles concurrents d’OpenAI (GPT-4o), de Google (Gemini 1.5 Pro) et même la nouvelle LLaMA 3 de Meta sur 7 tests de référence sur 9.
Google a riposté en fin 2024 avec Gemini, une famille de modèles conçue par Google DeepMind pour concurrencer GPT-4. Gemini 1.0 était déjà très performant et multimodal (texte + images), et début 2025 la version Gemini 1.5 (Flash ou Pro) améliore encore les capacités de code et de raisonnement, tout en offrant un contexte énorme d’environ 1 million de tokens (contre 128k tokens pour GPT-4o).
Des aperçus de Gemini 2.0/2.5 laissent entrevoir des performances de pointe, par exemple 99 % de réussite sur HumanEval en programmation pour Gemini 2.5 (résultats atteignant presque tous les problèmes résolus), ce qui le place au niveau des meilleurs modèles d’OpenAI.
Meta continue de jouer la carte de l’ouverture avec ses modèles LLaMA. Après LLaMA 2 (open source partiel en 2023) jusqu’à 70 milliards de paramètres, Meta travaille sur LLaMA 3 (surnommé LLaMA 3.1 dans certaines versions intermédiaires).
Ces modèles sont accessibles à la communauté, mais sous licence restreinte, et servent de base à de nombreux projets.
Néanmoins, leur domination est contestée : par exemple, le modèle chinois Hunyuan-Large de Tencent a dépassé Meta Llama 3.1 sur de multiples benchmarks. De plus, des acteurs indépendants comme Mistral AI (France) ont émergé.
Mistral a d’abord publié un LLM open source compact (7 milliards de paramètres) en 2023, puis a annoncé début 2024 Mistral Large, un modèle plus puissant (32k tokens de contexte) qui affiche des performances de haut niveau.
Mistral revendique que son modèle Large est devenu le second meilleur LLM disponible via une API, juste derrière GPT-4.
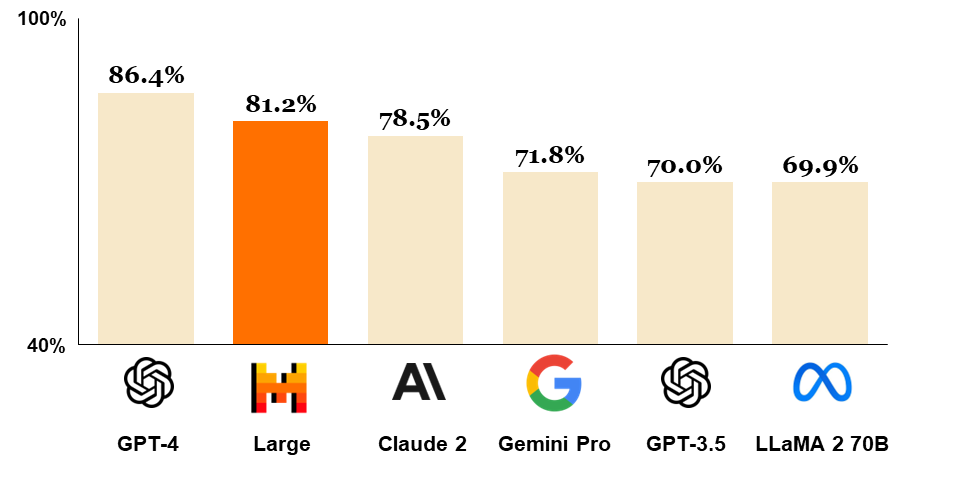
Ses scores de référence confirment cette position : fin 2023, GPT-4 atteignait environ 86 % sur le benchmark MMLU, contre ~81 % pour Mistral Large – surpassant ainsi Claude 2 (~78 %), Gemini 1.0 (~72 %) et LLaMA 2 70B (~70 %)
Enfin, DeepSeek s’impose comme l’invité surprise du classement. Fondée en 2023 à Hangzhou, cette start-up chinoise dirigée par Liang Wenfeng a recruté des chercheurs de haut niveau et adopté une approche très efficace en ressources.
Son modèle vedette DeepSeek-R1 (lancé en janvier 2025) a stupéfait le milieu de l’IA : R1 est un modèle de “raisonnement” ouvert qui rivalise avec les meilleurs systèmes d’OpenAI ou Google, tout en ayant été développé à une fraction du coût habituel.
En seulement deux mois de travail et avec moins de 6 millions USD de budget, DeepSeek avait déjà construit en 2024 un modèle de base (V3) très performant.
Puis R1, sa version orientée raisonnement, a été dévoilé début 2025 et a déclenché un véritable séisme : sa sortie a contribué à une chute boursière de plus de 1000 milliards de dollars dans le secteur technologique, les investisseurs réalisant soudain que la domination des acteurs américains pouvait être ébranlée.
En Chine, R1 a été accueilli triomphalement, des dizaines d’entreprises intégrant déjà ses capacités dans leurs produits.
Comparaison des performances techniques des modèles
Malgré des approches variées, tous ces LLM (Large Language Models) de pointe sont évalués sur des benchmarks standardisés permettant une comparaison IA objective. Voici un tour d’horizon des performances sur quelques tests clés en 2025 :
Raisonnement et connaissances (MMLU, Big Bench, etc.)
Le benchmark MMLU (Massive Multitask Language Understanding) mesure la capacité d’un modèle à répondre à des questions de connaissance générale et spécialisée (57 disciplines) de niveau universitaire. Sur ce terrain, GPT-4 restait la référence avec 86 % de réussite fin 2023
Cependant l’écart s’est réduit : Claude 3 et DeepSeek R1 se situent dans les mêmes eaux hautes des 80+ %, d’après les premiers tests.
En particulier, DeepSeek R1 a montré des compétences de raisonnement et de mathématiques comparables aux meilleurs modèles US.
Certaines sources indiquent même que R1 a surpassé le modèle OpenAI “o1” (une version récente de ChatGPT axée raisonnement) sur des épreuves pointues comme des examens de mathématiques avancées.
De son côté, Claude 3.5 revendique une légère avance sur GPT-4o et Gemini 1.5 dans plusieurs tests de logique et compréhension. Les modèles open source comme Mistral Large ou LLaMA 2 accusent encore un retard modéré (autour de 70–81 % sur MMLU
mais restent très compétitifs compte tenu de leur taille souvent inférieure. En somme, sur les tâches de raisonnement général, GPT-4 et Claude 3.5 mènent, mais DeepSeek R1 n’est pas loin derrière – une performance remarquable pour un nouveau venu – et il égale ou dépasse ChatGPT sur certains benchmarks ciblés.
Codage et résolution de problèmes (HumanEval, GSM8K, etc.)
Les capacités en programmation et en résolution de problèmes mathématiques sont devenues un critère majeur pour évaluer les LLM. Le benchmark OpenAI HumanEval teste la génération de code à partir d’énoncés de fonctions ; GPT-4 obtenait initialement ~80–85 % de réussite, et les versions améliorées tutoient désormais la quasi-perfection.
Google a annoncé que Gemini 2.5 (version de prévisualisation début 2025) atteint 99 % de réussite sur HumanEval – c’est-à-dire qu’il résout presque tous les exercices de code, un score comparable à GPT-4.5. Claude 4 (annoncé fin 2025) se spécialise aussi dans le code avec plus de 70 % sur des tests comme SWE-Bench, tandis que GPT-4.5 Turbo excelle sur Python (88 % sur HumanEval).
Sur les problèmes mathématiques, GSM8K (ensemble d’environ 8000 problèmes d’arithmétique scolaire) et le difficile concours MATH mettent à l’épreuve la capacité de chain-of-thought (raisonnement étape par étape).
GPT-4 était là encore leader en 2023, mais Claude 3.5 et OpenAI o3 ont été explicitement entraînés pour le raisonnement mathématique.
DeepSeek R1, qualifié de modèle de « raisonnement », s’est illustré en résolvant des problèmes inédits de mathématiques scientifiques, se plaçant au niveau des meilleurs sur un ensemble comme MATH-500.
Des chercheurs ont noté que R1 obtenait des scores extrêmement élevés sur certains jeux d’exercices de calculs complexes. Sur GSM8K également, les écarts se resserrent entre les tops models : une version 12B de Mistral (nommée Pixtral) a même réussi à surpasser Claude 3.5 et Gemini 1.5 sur ce test en 2024.
Globalement, pour le coding et les maths, OpenAI et Google mènent toujours la danse avec leurs dernières itérations, mais DeepSeek et d’autres open source démontrent une capacité de raisonnement automatique surprenante pour leur taille.
Longueur de contexte, architecture et mémoire
Un autre différenciateur clé est la longueur de contexte maximale, c’est-à-dire la quantité de texte que le modèle peut traiter en une fois.
Sur ce point, l’année 2024 a vu une course à l’augmentation du contexte : Claude 2/3 d’Anthropic acceptait déjà 100k à 200k tokens (soit des centaines de pages de texte), permettant par exemple d’ingérer de longs documents.
GPT-4o a étendu le contexte d’OpenAI à 128k tokens, contre 32k pour la version standard GPT-4. Google est allé encore plus loin : Gemini 1.5 offre 1 million de tokens de fenêtre contextuelle, un record qui autorise des analyses de données massives d’un seul tenant.
Les modèles open source suivent avec pragmatisme : Mistral Large propose 32k tokens et LLaMA 2 jusqu’à 100k via des techniques d’extension (attention grouped, etc.). DeepSeek R1 n’a pas révélé publiquement sa limite de contexte exacte, mais indique pouvoir « raisonner » sur des chaînes de pensée étendues.
On sait que DeepSeek a impressionné même Nvidia grâce à une technique innovante de « test-time scaling » optimisant l’utilisation de la mémoire GPU durant l’inférence.
Cela suggère une architecture efficace possiblement basée sur des mixture-of-experts (MoE) : en effet, des analyses indiquent que DeepSeek R1 utilise un mélange d’experts totalisant 671 milliards de paramètres virtuels, activés de manière parcimonieuse pour maintenir les coûts bas.
Cette approche permet d’obtenir la puissance d’un modèle géant tout en ne faisant tourner qu’une partie du réseau à chaque requête, ce qui est révolutionnaire en termes de coût.
Côté Meta et Mistral, on reste sur des architectures transformeur classiques mais optimisées (quantisation, distillation…).
À noter que la plupart des modèles de 2025 sont multi-modaux (texte, image, et même audio) : GPT-4 et Gemini savent analyser des images, Claude 3.5 comprend des documents complexes, et Mistral a lancé Pixtral 12B, sa première version multimodale en 2024.
DeepSeek de son côté est principalement textuel pour l’instant, se concentrant sur le noyau du langage et du raisonnement.
Capacités multilingues et spécialisations
Dans un monde globalisé, le multilinguisme est un atout majeur des LLM. OpenAI revendique que GPT-4 et ses successeurs maîtrisent plus de 95 langues, avec une haute performance notamment en anglais, français, espagnol, etc.
Claude supporte officiellement quelques langues (anglais, japonais, français…) mais a montré lors de tests qu’il pouvait répondre dans pratiquement n’importe quelle langue si les données d’entraînement étaient présentes.
Google Gemini est entraîné sur de nombreuses langues mais privilégie 38 langues principales dans sa version 1.5, ce qui couvre la majorité des locuteurs mondiaux.
Les modèles open source comme LLaMA 2 ou Mistral ont souvent un biais vers l’anglais (car les données publiques sont majoritairement anglophones), mais Mistral Large a été rendu nativement fluide en anglais, français, espagnol, allemand et italien, surpassant même LLaMA 2 sur des benchmarks MMLU en français, allemand, etc.
DeepSeek, quant à lui, bénéficie de son origine chinoise : son modèle a été entraîné sur d’énormes corpus en chinois et en anglais, et sa popularité en Chine a entraîné de nombreuses contributions de la communauté locale.
DeepSeek R1 peut donc converser en mandarin de façon native, ce qui le rend très intéressant pour le marché asiatique.
L’équipe annonce travailler sur l’amélioration du raisonnement multilingue dans la version R2 à venir, afin de pouvoir rivaliser aussi bien en français qu’en anglais par exemple.
À ce titre, DeepSeek a déjà indiqué que R2 viserait une meilleure programmation et la capacité de raisonner au-delà de l’anglais, pour réellement en faire un assistant global.
En somme, si GPT-4 et Claude demeurent des généralistes très forts dans toutes les langues majeures, DeepSeek possède un avantage incontestable en chinois et, grâce à son ouverture, pourrait combler rapidement les lacunes dans d’autres langues avec l’aide de la communauté.
Les forces de DeepSeek face aux géants de l’IA
Face aux mastodontes généralement fermés (OpenAI, Google, Anthropic gardant secrets leurs modèles et données), DeepSeek adopte une philosophie radicalement différente : l’open source intégral. Son modèle R1 est disponible librement, avec ses poids, son code et des explications techniques détaillées publiquement accessibles.
C’est une différence fondamentale : n’importe quel développeur, entreprise ou laboratoire peut télécharger, utiliser et améliorer DeepSeek à sa guise, sans passer par une API payante ou craindre un changement de politique d’accès.
Le capital-risqueur Marc Andreessen a salué DeepSeek comme « l’une des avancées les plus impressionnantes » qu’il ait vues, soulignant qu’en plus c’est « open source, un cadeau profond fait au monde ».
Cette transparence a deux conséquences positives : elle rassure sur la fiabilité (on peut auditer le modèle, vérifier les biais) et elle accélère l’innovation collaborative (la communauté peut entraîner des versions dérivées, corriger des failles, ajouter des fonctionnalités).
Deuxième atout de DeepSeek : le coût. R1 a été développé avec des moyens réduits en exploitant des GPU moins puissants disponibles en Chine, là où OpenAI ou Google dépensent des centaines de millions de dollars pour entraîner leurs modèles géants.
Concrètement, DeepSeek affirme avoir formé son modèle V3 de base pour ~5,6 M$ (à peine 10 % du coût de LLaMA 2 chez Meta), et R1 pour quelques millions de plus. Non seulement la R&D a coûté moins cher, mais à l’utilisation aussi DeepSeek est bien plus économique.
Par exemple, l’accès API à R1 (via des plateformes comme Together.ai) ne coûte qu’environ 7 $ par million de tokens générés, contre ~60 $ par million de tokens pour utiliser le modèle OpenAI équivalent (GPT-4/o1).
L’ordre de grandeur est frappant : 10 fois moins cher pour une qualité perçue très proche.
Cette accessibilité tarifaire abaisse la barrière d’entrée pour de nombreux acteurs : une PME, une start-up ou un chercheur individuel peuvent fine-tuner ou déployer DeepSeek sur leurs propres serveurs à faible coût, là où GPT-4 resterait hors de portée financière.
De plus, l’efficacité de DeepSeek en fait un modèle plus sobre énergétiquement : en nécessitant moins de calcul pour un résultat équivalent, il réduit l’empreinte carbone liée au déploiement des IA.
Troisième force de DeepSeek : son adoption rapide et son écosystème naissant, en particulier en Chine. Alors que les autorités chinoises étaient initialement méfiantes (DeepSeek avait massivement acheté des stocks de GPU, suscitant des interrogations réglementaires), le succès de R1 a été embrassé comme une fierté nationale.
Fin janvier 2025, l’application DeepSeek est même devenue l’app gratuite la plus téléchargée sur l’App Store américain, dépassant ChatGPT – un signal fort de l’enthousiasme du public.
En Chine, le gouvernement et les entreprises encouragent désormais son usage : on voit émerger tout un écosystème de startups qui bâtissent des services sur la base technologique de DeepSeek.
L’IA chinoise connaît ainsi un boom d’innovation, stimulé par DeepSeek et aussi par les contraintes (comme les sanctions américaines sur les puces) qui poussent à rivaliser d’ingéniosité.
Un investisseur résume : « DeepSeek a prouvé que les labos chinois peuvent produire des modèles de pointe malgré les restrictions ».
Cette effervescence open source se répercute à l’international : certains anticipent que les entreprises hors de Chine devront aussi adopter des modèles ouverts pour rester compétitives.
DeepSeek montre en effet qu’innover en IA n’est plus réservé aux géants californiens, et cela pourrait “briser le monopole” d’un petit nombre d’acteurs dominants, selon les experts.
Il convient de noter que DeepSeek n’est pas sans défis. Son ouverture implique que les mêmes garde-fous que les modèles commerciaux (filtrage des contenus illicites, respect de la vie privée) doivent être reproduits par les utilisateurs.
R1 s’aligne sur les exigences de censure chinoise – il évite par exemple les sujets politiquement sensibles et promeut les “valeurs socialistes fondamentales” conformément aux directives locales. Cette caractéristique peut limiter son attractivité dans certaines régions ou applications.
De plus, l’absence de données totalement publiques sur l’entraînement de DeepSeek (même s’il y a des publications techniques) peut soulever des questions de confiance – bien que, paradoxalement, certains trouvent les modèles open source plus dignes de confiance précisément parce qu’on peut examiner leur fonctionnement.
Enfin, la réaction des gouvernements occidentaux reste en débat : quelques pays ont interdit l’utilisation de DeepSeek par crainte pour la confidentialité des données, montrant que même un modèle ouvert peut susciter des réticences géopolitiques.
Malgré tout, la dynamique enclenchée par DeepSeek semble difficile à arrêter : l’IA évolue vers davantage d’ouverture, de collaboration et de partage, une démocratisation de l’IA dont DeepSeek est le symbole en 2025.
Évolutions récentes des grands modèles (2024–2025)
L’année écoulée a été riche en nouveautés du côté des meilleurs modèles IA 2025, ce qui contextualise l’arrivée de DeepSeek.
Chez OpenAI, après GPT-4, l’attention s’est portée sur la série dite “GPT-o” : GPT-4o a été déployé pour offrir une version optimisée/allégée de GPT-4 fin 2024, suivie par OpenAI o3 (début 2025) orienté explicitement vers le raisonnement scientifique et mathématique.
OpenAI a également annoncé en 2025 travailler sur un modèle open source, signe de l’influence de la tendance initiée par DeepSeek, bien que ce modèle libre se fasse attendre.
Anthropic a fait évoluer Claude très rapidement : Claude 3 (début 2024) a doublé la taille de contexte et amélioré l’alignement, puis Claude 3.5 “Sonnet” (mi-2024) a encore augmenté la vitesse (2× plus rapide) et intégré des données d’entraînement supplémentaires (y compris images).
Fin 2024, Anthropic a ajouté des fonctionnalités comme Artifacts pour éditer les réponses de l’IA en temps réel, ciblant une intégration fluide en entreprise.
Début 2025, des rumeurs de Claude 4 pointent un cap vers 1 billion de paramètres effectifs via des techniques d’ensemble, faisant de Claude un sérieux candidat au titre de modèle le plus puissant.
Google/DeepMind, avec Gemini, a adopté une stratégie de versions progressives : Gemini 1.0 (fin 2024) a impressionné par ses capacités multimodales et de planification (héritées d’AlphaGo).
Puis Gemini 1.5 (début 2025) est sorti en variantes Flash (rapide, pour usage grand public) et Pro (maximisant la qualité pour clients professionnels).
Gemini 1.5 Pro a notamment introduit la fonction de tuning de prompt et l’appel d’outils externes (API) de manière native.
Google a également travaillé sur la transparence : une initiative d’« IA ouverte et sûre » a abouti à la sortie de modèles Gemini plus petits dont le fonctionnement est mieux explicable.
La version Gemini 2.0 en test privé pousserait encore les limites, avec possiblement la capacité de traiter 10 millions de tokens et d’intégrer un module de moteur de recherche interne pour combler ses lacunes de connaissances en temps réel (non confirmé officiellement).
Côté Meta, l’open source a continué via des collaborations externes. En 2024, Meta a soutenu des projets comme HuggingFace pour lancer LLaMA 2 Chat 70B, tout en préparant LLaMA 3.
Ce dernier, dont une version 3.1 circule début 2025, a amélioré le suivi d’instructions et la stabilité des réponses.
Toutefois, Meta fait face à la concurrence frontale des start-ups : Mistral AI a sorti son Mistral Large (voir plus haut), disponible via API et même sur Azure, ce qui indique un écosystème commercial autour de ce modèle européen.
Mistral a également proposé un ensemble de 8 modèles 7B combinés (surnommé Mixtral 8×7B) pour concurrencer des modèles plus gros en restant open-source.
En septembre 2024, la sortie de Pixtral 12B – le premier modèle multimodal de Mistral – a marqué une étape dans la réponse européenne à GPT-4.
Pendant ce temps en Chine, outre DeepSeek, les géants locaux se sont mobilisés : Alibaba a ouvert son modèle Qwen-7B en open source et investi 2 milliards $ dans le cloud AI, Baidu a lancé sa version gratuite d’Ernie Bot, ByteDance a son modèle Doubao 1.5 low-cost, etc.
Tout cet élan a été en partie catalysé par DeepSeek : son succès a poussé les acteurs à accélérer leurs sorties de modèles pour ne pas être distancés.
Il se dessine ainsi une course à l’IA où l’ouverture (du code, des poids) et l’efficacité sont devenues tout aussi importantes que la performance brute.
Conclusion : DeepSeek dans le classement des meilleurs LLM de 2025
En synthèse, DeepSeek R1 s’est hissé parmi les meilleurs modèles IA de 2025, au coude-à-coude avec les modèles d’OpenAI, Google, Anthropic, Meta ou Mistral sur de nombreux critères techniques.
Ses scores dans les benchmarks de performance (MMLU, HumanEval, etc.) confirment qu’un modèle open source à budget modéré peut rivaliser avec les ténors fermés – il égale ChatGPT sur certaines tâches de raisonnement et approche son niveau dans l’ensemble.
Surtout, DeepSeek apporte une philosophie différente : en ouvrant son modèle, en cassant les prix et en prouvant qu’innovation peut rimer avec collaboration ouverte, il a changé la donne du marché de l’IA.
Pour les utilisateurs (grand public, développeurs, entreprises), cela signifie plus de choix et de transparence : on peut choisir entre la puissance éprouvée d’un GPT-4 (sous réserve de moyens financiers conséquents) ou la flexibilité d’un DeepSeek (gratuit, modulable, auto-hébergeable).
Pour la communauté scientifique, DeepSeek est une aubaine qui permet de décortiquer un modèle de très haut niveau et d’apprendre de ses méthodes.
Pour l’industrie, c’est un signal que l’ère des boîtes noires ultra-coûteuses pourrait toucher à sa fin, remplacée par une ère de commoditisation des LLM où la différence se fera plus sur les applications concrètes que sur le modèle lui-même.
D’ailleurs, comme le souligne un analyste, si l’on ne distingue plus la qualité des réponses d’un modèle open source à 7 $ et d’un modèle propriétaire à 60 $, « pourquoi payer plus cher ? ».
Bien sûr, la compétition continue d’avancer. OpenAI, Google et consorts préparent déjà la prochaine génération (GPT-5, Gemini 2, Claude 4, LLaMA 3…) qui pourrait reprendre de l’avance en 2026.
(Découvrez dès maintenant la puissance de GPT-5 sur la plateforme Chat Got — une interaction intelligente, des performances exceptionnelles et des possibilités infinies. Cliquez ici pour commencer !)
DeepSeek de son côté ne compte pas s’arrêter à R1 : la version DeepSeek R2 est attendue avec des capacités accrues (meilleure programmation, raisonnement multilingue amélioré).
Si elle tient ses promesses, elle renforcera encore la position de DeepSeek parmi les leaders de l’IA en 2025.
Quoi qu’il en soit, l’irruption de DeepSeek aura eu un mérite indéniable : démocratiser l’IA de pointe et inciter tous les acteurs, grands comme petits, à innover plus vite et à revoir leur stratégie.
L’« effet DeepSeek » – comparable à un moment Sputnik pour l’IA – se traduit par une émulation mondiale dont bénéficient à la fois la recherche, l’industrie et le grand public.
L’année 2025 aura été celle où le monopole de quelques modèles fermés a cédé la place à un classement des modèles IA beaucoup plus ouvert, diversifié et dynamique, avec DeepSeek solidement installé dans le peloton de tête.


