
Le laboratoire DeepSeek vient de dévoiler son nouveau modèle DeepSeek-R1-0528, une mise à jour majeure de son modèle de langage axé sur le raisonnement (R1).
Sorti discrètement fin mai 2025, ce modèle open-source s’adresse aux chercheurs en intelligence artificielle et se positionne d’emblée comme un rival des plus grands modèles propriétaires d’OpenAI et Google.
Comme son prédécesseur, R1-0528 est distribué sous licence permissive (MIT), avec des poids open-source disponibles sur HuggingFace, ce qui autorise une utilisation et une personnalisation libres, y compris pour des usages commerciaux.
Cette approche ouverte permet à la communauté d’examiner le modèle en détail et de l’intégrer dans leurs propres applications, illustrant la volonté de DeepSeek de « soutenir la communauté de recherche » en partageant ses avancées.
Dans cet article, nous analysons en profondeur ce modèle R1-0528 : ses améliorations par rapport aux versions précédentes, son architecture technique et son entraînement par apprentissage par renforcement, ses performances sur divers benchmarks (mathématiques, code, raisonnement…), les nouvelles fonctionnalités introduites, ainsi que son accessibilité et ses applications potentielles.
Architecture technique et apprentissage par renforcement
Le modèle DeepSeek-R1-0528 s’appuie sur une architecture de transformeur à Mixture-of-Experts (MoE) à très grande échelle.
Concrètement, il comporte 671 milliards de paramètres au total, dont environ 37 milliards sont activés pour chaque requête, grâce à des experts spécialisés sélectionnés dynamiquement par un module de gating.
Cette conception MoE permet d’accroître la capacité du modèle sans faire exploser le coût d’inférence, puisque seule une partie des paramètres est utilisée à chaque prédiction.
De plus, R1-0528 peut traiter un contexte d’entrée allant jusqu’à 128 000 tokens, ce qui lui autorise des raisonnements très détaillés sur de longues entrées (par exemple analyser de longs documents ou enchaîner de nombreuses étapes de calcul).
Du côté de l’entraînement, DeepSeek-R1-0528 est le fruit d’un pipeline multi-étapes intégrant fortement l’apprentissage par renforcement pour favoriser le raisonnement.
Son développement s’est appuyé sur un modèle de base (nommé DeepSeek-V3-Base) affiné via quatre étapes successives, combinant génération de données de raisonnement, fine-tuning supervisé et renforcement.
Dans un premier temps, les chercheurs ont effectué un pré-entraînement “cold start” supervisé sur des milliers d’exemples synthétiques de « chaines de pensée » (Chain-of-Thought, CoT) détaillées, générées par différents procédés (prompting du modèle de base avec des exemples de raisonnement, auto-réflexion du modèle sur ses propres solutions, puis intervention d’annotateurs humains pour affiner les outputs).
Ensuite, une phase d’apprentissage par renforcement a été menée à grande échelle, en s’appuyant notamment sur l’algorithme Group Relative Policy Optimization (GRPO).
Cette méthode de renforcement a permis d’améliorer la capacité du modèle à résoudre des problèmes complexes en lui attribuant des récompenses adaptées : par exemple, pour des problèmes mathématiques, le modèle était récompensé à la fois pour la justesse du résultat final (récompense d’exactitude) et pour la présentation explicite de ses étapes de raisonnement au format attendu (récompense de format).
Ainsi, R1 a appris non seulement à trouver la bonne réponse, mais aussi à développer sa solution de manière lisible (avec des balises de type <think> indiquant ses étapes internes) – une stratégie qui le distingue des LLM classiques nécessitant un prompt explicite pour déclencher un raisonnement pas-à-pas.
Cette approche rejoint l’objectif affiché par DeepSeek d’« encourager le développement de capacités de raisonnement sans données supervisées » en s’appuyant sur un processus d’auto-amélioration guidé par le RL.
Enfin, les itérations successives du modèle ont été utilisées pour auto-générer un large corpus de nouvelles données d’entraînement : environ 600 000 réponses à des questions de raisonnement produites par des versions intermédiaires de R1, dont seules les réponses correctes ont été retenues pour un affinement supplémentaire, complétées par 200 000 exemples hors raisonnement (traduction, etc.) afin de préserver des compétences générales du modèle.
Au terme de ce processus de formation complexe (incluant donc RL sans et avec amorce supervisée, filtrage par rejection sampling, puis affinement final), DeepSeek-R1 a atteint un niveau de performance élevé comparable aux modèles OpenAI de la série o1 sur les tâches de raisonnement, d’après l’équipe.
DeepSeek souligne que l’ajout d’une petite quantité de données supervisées “cold-start” avant le RL a joué un rôle clé pour dépasser les limitations de la version purement renforcée R1-Zero, combinant ainsi le meilleur des deux mondes (un boost initial dirigé et une amélioration auto-supervisée à grande échelle).
Performances sur les benchmarks
Les améliorations apportées par DeepSeek R1-0528 se traduisent par des sauts de performances significatifs sur de nombreux benchmarks standard en IA, qu’il s’agisse de problèmes mathématiques, de génération de code ou de questions de connaissance et de raisonnement général.
Selon la fiche technique publiée par DeepSeek, ces progrès sont le résultat d’un accroissement des ressources de calcul allouées ainsi que de nouvelles optimisations algorithmiques en post-entraînement, permettant au modèle de pousser plus loin ses capacités d’inférence et de réflexion.
L’équipe de développement a évalué R1-0528 sur des batteries de tests variées et comparé ses scores à la version précédente R1 et aux modèles les plus avancés du marché.
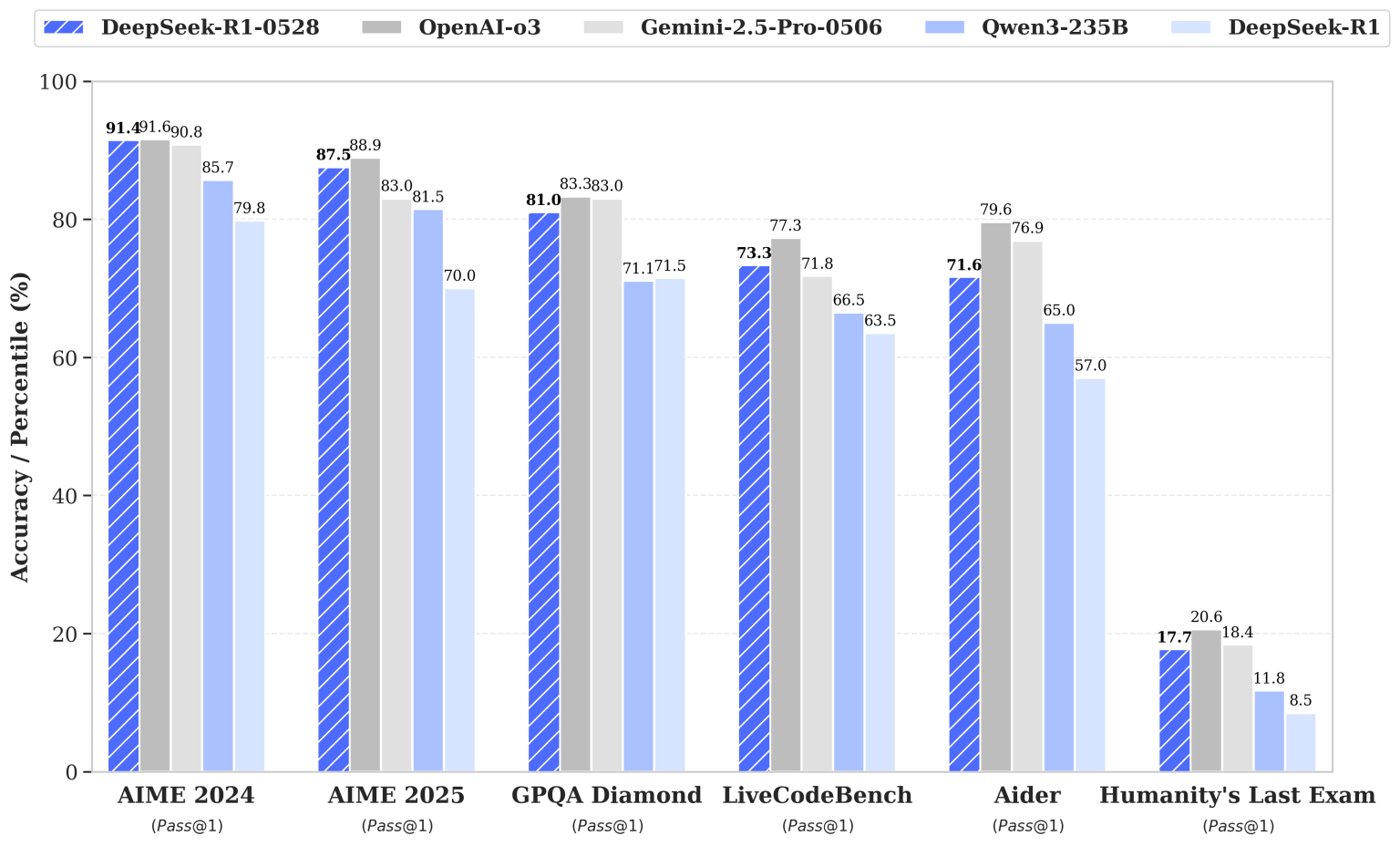
Comparaison des scores de DeepSeek-R1-0528 (barres bleues hachurées) par rapport à plusieurs modèles de pointe – OpenAI o3 (gris), Google Gemini-2.5-Pro-0506 (noir), Qwen3-235B (bleu clair)* – ainsi qu’à l’ancienne version DeepSeek-R1 (bleu clair uni), sur divers benchmarks (pourcentages de réussite en Pass@1 ou précision).
On constate que R1-0528 atteint pratiquement le niveau du modèle propriétaire d’OpenAI sur les épreuves mathématiques de l’AIME (American Invitational Mathematics Exam) : par exemple, il obtient 91,4 % de réussite sur l’AIME 2024, tout juste en dessous du 91,6 % du modèle o3, et devance le modèle de Google Gemini 2.5 (90,8 %).
De même sur l’AIME 2025, R1-0528 frôle le score d’OpenAI (87,5 % vs ~88,9 %) tout en surpassant celui de Gemini 2.5.
Ces progrès spectaculaires représentent un bond de +17,5 points par rapport à la version R1 précédente (qui plafonnait à 70 % sur AIME 2025) – une amélioration rendue possible par une profondeur de raisonnement accrue (le modèle traite en moyenne 23 000 tokens par question mathématique, contre 12 000 auparavant, ce qui lui permet d’explorer plus d’étapes de calcul).
Les performances de DeepSeek-R1-0528 s’illustrent également dans le domaine du code.
Sur le benchmark LiveCodeBench (résolution de problèmes de programmation), son taux de réussite est monté à 73,3 %, contre 63,5 % pour la version précédente.
Cet écart le place devant le modèle de Google sur ce test, même s’il reste légèrement derrière le modèle d’OpenAI (qui dépasse 77 %).
De plus, son niveau en compétitions de code Codeforces Division 1 équivaut désormais à un classement Elo ~1930, en forte hausse par rapport aux ~1530 de R1 – le propulsant du niveau “participant moyen” à celui d’un candidat maître en programmation compétitive.
Sur SWE-Verified (résolution automatique de défis de génie logiciel), R1-0528 résout 57,6 % des problèmes contre 49 % auparavant, et sur le challenge multi-langage Aider-Polyglot, son taux de réussite atteint 71,6 % (vs ~53 % pour R1).
Un développeur early-adopter a même témoigné sur X que « DeepSeek-R1-0528 est incroyable en codage », notant que le modèle a généré du code propre accompagné de tests unitaires passants du premier coup pour un défi algorithmique, une prouesse qu’il n’avait vue jusque-là que chez le modèle o3 d’OpenAI.
Sur des tâches de raisonnement et de Q&A complexes, R1-0528 confirme également son avance.
Par exemple, sur le difficile test “Humanity’s Last Exam” (une évaluation de questions extrêmement ardues), le taux de réussite du modèle a plus que doublé, passant de 8,5 % à 17,7 %.
S’il s’agit en valeur absolue d’un score modeste (les questions étant conçues pour être quasi-impossibles), cette progression illustre une nette amélioration de la capacité de réflexion du modèle sur les cas les plus tordus.
De même, sur GPQA-Diamond (un benchmark de questions-réponses à pièges), R1-0528 atteint 81,0 % en pass@1 contre 71,5 % auparavant.
Sur l’ensemble de ces benchmarks de haut niveau, le nouveau modèle distancie confortablement l’ancienne version R1 et réduit considérablement l’écart avec les ténors fermés du domaine.
En fait, d’après les résultats internes communiqués par DeepSeek, R1-0528 se hisse au coude-à-coude avec les meilleurs modèles d’OpenAI (o3) et de Google (Gemini 2.5 Pro) – tout en demeurant gratuit et sans restrictions d’accès là où les modèles concurrents sont payants ou limités.
Nouvelles fonctionnalités et fiabilité accrue
Au-delà des gains de performance bruts, DeepSeek-R1-0528 apporte son lot de nouvelles fonctionnalités et d’améliorations qualitatives qui le rendent plus pratique à utiliser pour les développeurs et chercheurs.
L’une des nouveautés majeures est le support natif des sorties JSON et de l’appel de fonctions (function calling).
Concrètement, le modèle peut désormais générer directement des réponses structurées en format JSON ou appeler des fonctions externes selon les instructions, ce qui facilite grandement son intégration dans des applications complexes (agents logiciels, systèmes à outils, automatisation de workflows, etc.).
Cette capacité à produire des formats structurés fiables répond à un besoin fréquent pour interfacer un LLM avec d’autres systèmes, et rapproche R1-0528 de ce que proposent des IA comme GPT-4 via l’API OpenAI (mais ici en open-source).
Par ailleurs, l’expérience côté interface utilisateur a été peaufinée (« front-end capabilities refined » selon DeepSeek) afin de rendre les interactions plus fluides et efficaces.
Par exemple, un “mode système” dédié a été introduit pour piloter le comportement du modèle : alors que la version précédente requérait un jeton spécial inséré en début de prompt ou de réponse pour activer le mode « réflexion approfondie », cette astuce n’est plus nécessaire dans R1-0528.
Le déploiement s’en trouve simplifié – plus besoin d’ajouter manuellement un indicateur caché pour obtenir du modèle qu’il déroule son raisonnement, l’agent de conversation peut directement être configuré via l’invite système standard.
Un autre point crucial est la réduction du taux d’hallucinations. Les concepteurs annoncent que R1-0528 est moins enclin à produire des informations factuellement fausses ou incohérentes qu’auparavant.
Cette amélioration de la fiabilité a son importance pour un usage en production ou dans des contextes critiques : elle signifie que le modèle a gagné en alignement et en capacité à s’autocorriger, probablement grâce aux raffinements apportés en post-entraînement et aux retours de la communauté.
En parallèle, DeepSeek mentionne avoir amélioré l’expérience de « vibe coding », un concept émergent de développement assisté par IA où le code est co-écrit de manière intuitive et interactive avec le modèle.
En pratique, cela se traduit par un modèle plus cohérent dans le suivi des instructions de codage, capable de tenir compte du contexte global du projet et de générer du code qui “colle au besoin” avec un minimum d’aller-retours.
Bien que le terme vibe coding reste informel, l’idée est que R1-0528 facilite un flux de travail de programmation naturel, où le développeur décrit ce qu’il veut faire et l’IA produit le squelette ou la solution correspondante, dans un style fluide et créatif.
Les retours précoces d’utilisateurs semblent confirmer que ce modèle excelle désormais dans ce rôle d’assistant de codage (certains n’hésitant pas à le qualifier de meilleur modèle de code open-source actuel).
En résumé, ces nouvelles fonctionnalités – sorties structurées, appels de fonctions, mode de raisonnement natif, moindre hallucination – font de DeepSeek-R1-0528 un modèle plus robuste et mieux outillé pour s’intégrer dans des environnements réels.
L’interopérabilité est améliorée, les réponses sont plus fiables, et l’utilisateur dispose d’un meilleur contrôle sur le comportement de l’IA.
Ces aspects sont particulièrement importants pour les chercheurs souhaitant expérimenter avec le modèle (par exemple l’utiliser comme agent planificateur, solveur de problèmes scientifiques, ou assistant de programmation) sans se heurter à des limitations artificielles.
Disponibilité open-source et variantes allégées
L’un des atouts majeurs de DeepSeek-R1-0528 réside dans sa disponibilité et son accessibilité pour la communauté.
Le modèle complet est téléchargeable librement, et son code source est consultable, sous licence MIT.
Les poids du modèle (y compris ceux de la nouvelle version 0528) ont été publiés sur Hugging Face peu après l’annonce, sans fanfare particulière – une sortie quasi « stealth » où DeepSeek a simplement mis en ligne le modèle et laissé la communauté le découvrir d’elle-même.
En quelques heures, développeurs et chercheurs se sont emparés de R1-0528, le testant sur divers cas d’usage et partageant leurs résultats, témoignage de l’engouement pour les alternatives ouvertes de haut niveau.
Pour ceux qui souhaitent essayer le modèle en ligne, DeepSeek propose également une interface web gratuite sur son site officiel, accessible après une simple inscription (validation par numéro de téléphone ou compte Google).
De plus, DeepSeek offre une API compatible OpenAI permettant d’intégrer R1-0528 dans des applications externes ; les utilisateurs de la plateforme DeepSeek ont d’ailleurs été automatiquement migrés vers le nouveau modèle sans surcoût.
Le tarif de l’API reste très compétitif par rapport aux offres d’OpenAI : autour de 0,55 $ par million de tokens en entrée et 2,19 $ par million de tokens générés, soit une fraction du coût d’un GPT-4 (o1) équivalent.
Cela reflète la mission de DeepSeek de démocratiser l’accès aux modèles de pointe en levant les barrières financières et techniques.
Il faut souligner que si le modèle R1-0528 complet est extrêmement puissant, il est aussi très volumineux : en format plein, ses 671 milliards de paramètres occupent plus de 700 Go en mémoire.
Une instance non quantifiée nécessite des infrastructures lourdes pour tourner à pleine capacité. Consciente de cet obstacle, l’équipe a travaillé sur des solutions pour rendre le modèle plus léger.
D’une part, ils ont publié des versions quantifiées du modèle (via des formats GGUF optimisés) permettant de faire tourner R1-0528 avec seulement 180 Go environ, grâce à des quantifications mixtes (certaines couches MoE en très basse précision, d’autres en 4-6 bits) qui réduisent la taille de 75 % sans perte majeure de performance.
D’autre part, DeepSeek a également dévoilé une variante distillée beaucoup plus petite : DeepSeek-R1-0528-Qwen3-8B.
Ce modèle de 8 milliards de paramètres a été obtenu en distillant les chaînes de raisonnement de R1-0528 dans un modèle base Qwen-3 de 8B.
Le but est de rendre les avancées de R1 accessibles à ceux qui ne disposent pas de GPU haute mémoire.
Selon DeepSeek, cette version 8B atteint des performances état-de-l’art parmi les modèles open-source de sa taille, égalant par exemple les scores d’un modèle Qwen3 de 235B sur certains tests comme AIME 2024.
Elle dépasse de +10 % le modèle Qwen3-8B original sur les tâches de raisonnement mathématique.
Un seul GPU grand public (16 Go de VRAM) suffit à la faire tourner en FP16, ce qui la met à la portée de nombreux laboratoires académiques et développeurs indépendants.
DeepSeek voit dans cette démarche de distillation une opportunité de favoriser la recherche et les applications industrielles sur des modèles plus modestes, tout en bénéficiant des capacités de raisonnement acquises par le grand modèle.
En somme, que ce soit via le modèle complet pour des besoins ultimes en performance, ou via des déclinaisons allégées pour une utilisation locale plus aisée, DeepSeek-R1-0528 se veut accessible au plus grand nombre et modulable en fonction des contraintes de calcul de chacun.
Applications potentielles
Les performances et fonctionnalités de DeepSeek-R1-0528 ouvrent la voie à un large éventail d’applications dans le domaine de l’intelligence artificielle, en particulier pour des tâches nécessitant un raisonnement approfondi.
Voici quelques domaines où ce modèle de pointe pourrait apporter une valeur ajoutée significative :
- Résolution de problèmes mathématiques avancés : Étant donné les scores quasi-humains de R1-0528 sur des compétitions comme l’AIME ou HMMT, il peut servir d’assistant mathématique capable de résoudre des problèmes olympiques, d’aider à la démonstration de théorèmes ou de vérifier des solutions complexes. Des chercheurs en mathématiques ou en éducation pourraient l’exploiter pour générer des explications pas-à-pas, créer des banques d’exercices résolus, ou explorer de nouvelles méthodes de résolution via l’analyse des cheminements de l’IA. Son entraînement axé CoT le rend apte à montrer son raisonnement, ce qui est précieux dans un contexte pédagogique ou de recherche où la transparence du raisonnement est aussi importante que le résultat final.
- Génération de code et génie logiciel : R1-0528 s’est distingué par sa capacité à écrire du code correct et même à concevoir des tests unitaires qui passent du premier coup. Cela en fait un excellent candidat pour un assistant de programmation de nouvelle génération. On peut envisager son intégration dans des IDE ou plateformes de code (à l’image de GitHub Copilot, mais en plus puissant et open-source) pour aider les développeurs à écrire des fonctions complexes, déboguer du code, ou migrer du code d’un langage à un autre. Sa compréhension contextuelle sur 128k tokens lui permettrait de gérer de grands projets ou dépôts entiers, offrant des suggestions cohérentes à l’échelle d’un projet logiciel complet. De plus, le support du function calling autorise la connexion de R1-0528 à des environnements d’exécution ou des outils (par ex. accéder à une base de données, appeler une API externe), ce qui ouvre des possibilités d’agents de développement capables de réaliser des actions (création de fichiers, exécution de code, etc.) en suivant le dialogue avec le programmeur.
- Assistants virtuels et analyse de données : Grâce à sa réduction d’hallucinations et sa capacité à produire du JSON structuré, R1-0528 pourrait être employé comme moteur de question-réponse fiable sur des bases de connaissances spécialisées (juridiques, médicales, techniques). Par exemple, une entreprise pourrait le fine-tuner sur son corpus interne pour obtenir un assistant capable de raisonner sur des données métier complexes et fournir des rapports ou recommandations argumentées. En recherche scientifique, il pourrait aider à formuler des hypothèses en analysant de grandes quantités de textes et en tirant des conclusions logiques. Son aptitude à la déduction pourrait s’avérer utile pour des tâches d’analyse de données complexes, où il faut chaîner plusieurs étapes de raisonnement (p. ex. analyser des résultats expérimentaux en combinant des explications littéraires et des calculs).
- Systèmes multi-agents et planification : Le fait que R1-0528 soit open-source et qu’il supporte les appels de fonction le rend tout indiqué pour être le cerveau de systèmes multi-agents ou d’agents planificateurs. On peut imaginer des pipelines où R1-0528 décompose un objectif en sous-tâches, appelle des outils (via l’API fonctionnelle) pour obtenir des informations en temps réel, puis synthétise un plan d’action. Sa longue fenêtre de contexte permet de conserver en mémoire l’historique complet de la planification. Des chercheurs en automatisation et robotique pourraient tirer parti de ces capacités pour développer des agents plus autonomes et explicables, en combinant R1-0528 avec des capteurs ou des environnements simulés.
En outre, du fait de son ouverture, DeepSeek-R1-0528 constitue lui-même un objet de recherche.
Les académiques en IA pourront analyser en détail ses poids, ses prompts intermédiaires de réflexion, et la manière dont émergent ses stratégies de résolution.
L’équipe DeepSeek a mis en avant l’importance de la « chaine de pensée » apprise par R1-0528, estimant qu’elle « aura une importance significative pour la recherche académique sur les modèles de raisonnement ».
Étudier comment le modèle parvient à ses conclusions (et éventuellement où il échoue) peut aider à mieux comprendre les mécanismes de raisonnement des LLMs et à concevoir de futurs modèles encore plus performants.
De plus, la disponibilité de versions distillées plus légères facilite les expérimentations : par exemple, intégrer la version 8B dans un projet de recherche universitaire sans nécessiter une infrastructure coûteuse, ou comparer les performances d’un petit modèle entraîné avec ou sans ces chains-of-thought issues de R1-0528.
Enfin, il convient de noter que ce lancement R1-0528 s’inscrit peut-être dans une stratégie plus large de DeepSeek.
Certains observateurs voient en lui le dernier rafinement de la première génération R1 avant l’arrivée prochaine d’un éventuel DeepSeek-R2, annoncé comme le prochain frontier model de l’équipe.
Si tel est le cas, R1-0528 aura non seulement comblé l’écart avec l’état de l’art actuel, mais il aura aussi pavé la voie pour la suite.
Quoi qu’il en soit, en combinant des progrès mesurables sur les benchmarks, des fonctionnalités pratiques pour l’utilisateur et une philosophie open-source, DeepSeek-R1-0528 se présente comme un outil précieux pour les développeurs, chercheurs et innovateurs désireux de repousser les limites du raisonnement automatique tout en gardant la maîtrise de leur IA.


