
La start-up d’intelligence artificielle chinoise DeepSeek a annoncé le lancement officiel de son nouveau modèle DeepSeek-V3 0324 le 25 mars 2025. Ce modèle de grande langue open source représente une mise à jour majeure de la version V3 initiale.
Publié sous licence open source MIT, il est distribué librement via la plateforme Hugging Face, marquant la volonté de DeepSeek de rivaliser avec les géants occidentaux de l’IA sur un mode ouvert.
Le modèle promet des performances en hausse par rapport à son prédécesseur, notamment en matière de raisonnement et de codage informatique, d’après les premiers tests publiés.
Caractéristiques techniques et performances du modèle
Le modèle DeepSeek-V3 0324 s’appuie sur une architecture novatrice dite « Mixture-of-Experts » (MoE), ou mélange d’experts, qui lui permet d’atteindre une taille record tout en optimisant l’efficacité. Concrètement, il totalise 671 milliards de paramètres, mais seulement environ 37 milliards sont activés par requête grâce à ce système MoE.
Cela équivaut à mobiliser dynamiquement une poignée de sous-modèles experts pour chaque question posée, plutôt qu’un seul modèle géant – une approche qui réduit le coût de calcul sans sacrifier la performance.
Ce modèle supporte en outre un contexte étendu de 128 000 tokens, lui permettant de traiter des documents ou conversations très longs.
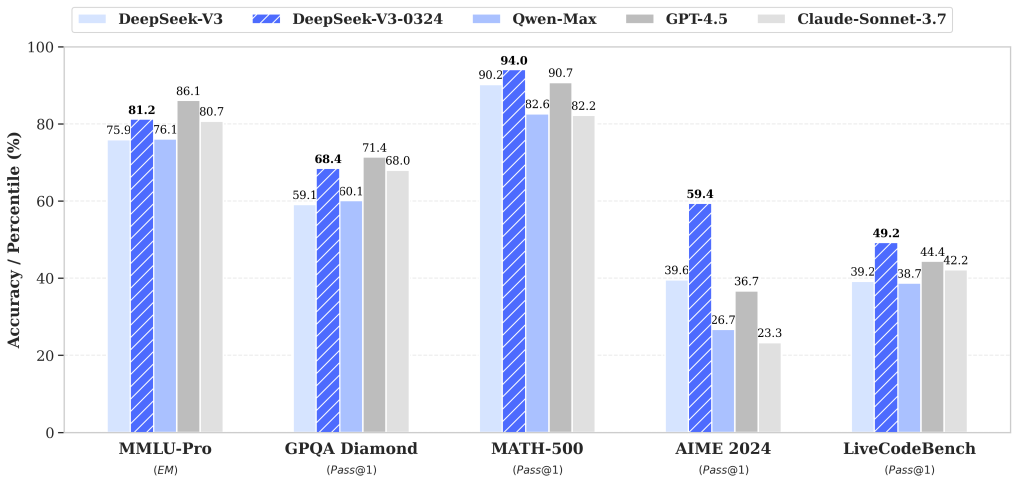
Performances. DeepSeek-V3 0324 affiche des progrès significatifs sur de nombreux benchmarks d’IA par rapport à la version V3 précédente.
Par exemple, son score au test académique MMLU-Pro (évaluation de connaissances de niveau universitaire) est passé de 75,9 % à 81,2 % (+5,3 points), et celui au benchmark de questions-réponses générales GPQA de 59,1 % à 68,4 % (+9,3).
Sur une épreuve de raisonnement mathématique avancé (AIME), il bondit de 39,6 % à 59,4 % (+19,8 points), tandis que sur un test de programmation comme LiveCodeBench, il progresse de 39,2 % à 49,2 % (+10 points). Ces améliorations de capacité de raisonnement et de résolution de problèmes placent désormais DeepSeek-V3 0324 parmi les modèles les plus performants de sa catégorie.
Graphique : Comparatif des performances de DeepSeek-V3 (barres bleu clair) et de DeepSeek-V3 0324 (barres bleu hachuré) sur plusieurs benchmarks, face à des modèles concurrents (Alibaba Qwen-Max, GPT-4.5 d’OpenAI et Claude 3.7 Sonnet d’Anthropic). DeepSeek-V3 0324 surpasse nettement son prédécesseur V3 sur tous les tests, et rivalise avec les meilleurs modèles propriétaires – notamment en mathématiques (MATH-500) et en programmation (LiveCodeBench).
Au-delà des chiffres de benchmarks, le modèle démontre des capacités techniques étendues. Il excelle particulièrement dans les tâches spécialisées : il a ainsi obtenu un score de 92 % au test de codage HumanEval (évaluation de la qualité du code généré) et 85 % au défi mathématique MATH-500, témoignant d’aptitudes élevées en programmation et en raisonnement mathématique.
Ces résultats, proches de ceux de modèles fermés très avancés, ont été salués par la communauté scientifique – le chercheur Yann LeCun a même qualifié le modèle « d’excellent ».
Sur un indice de qualité global combinant divers benchmarks, DeepSeek-V3 0324 a atteint 80 points sur 100, le plaçant dans le haut du tableau aux côtés de systèmes propriétaires comme Google Gemini 1.5 Pro ou Claude 3.5, et au-dessus de tous les autres modèles open source disponibles à ce jour.
Efficacité et coût d’entraînement. Un atout majeur de DeepSeek-V3 0324 réside dans son efficacité exceptionnelle en termes d’entraînement.
Malgré son échelle colossale, le modèle a été entraîné en seulement 57 jours sur environ 2 000 GPU Nvidia H800 (versions bridées pour la Chine), représentant ~2,78 millions d’heures de calcul.
DeepSeek estime le coût total de cette formation à moins de 6 millions de dollars, une somme dérisoire comparée aux centaines de millions investis habituellement pour des modèles de capacité équivalente chez OpenAI ou Meta.
Ce niveau d’efficience – obtenu via des optimisations logicielles (précision mixte FP8, algorithmes de communication optimisés) et l’architecture MoE – montre qu’il est possible de rivaliser avec les géants de l’IA sans disposer des ressources illimitées de la Silicon Valley.
Évolution des modèles DeepSeek : de V1 à V3-0324
Le modèle V3 0324 s’inscrit dans la continuité d’une progression rapide de DeepSeek en l’espace de deux ans. Voici un aperçu des versions précédentes et de leurs avancées :
- DeepSeek LLM (V1) – Décembre 2023. Premier modèle généraliste de DeepSeek, lancé peu après la création de l’entreprise. D’environ 67 milliards de paramètres, il a posé les bases de l’assistant IA de la start-up, avec déjà une orientation open source.
- DeepSeek-V2 – Mai 2024. Deuxième génération de LLM, introduisant une première version de l’architecture MoE pour gagner en puissance tout en réduisant les coûts d’entraînement. DeepSeek-V2 a amélioré les performances par rapport à V1 tout en consommant ~42 % de ressources en moins grâce à ses innovations techniques (par ex. cache mémoire optimisé).
- DeepSeek-V3 (V3 initial) – Décembre 2024. Troisième itération majeure, marquée par un changement d’échelle spectaculaire. V3 adopte pleinement l’architecture Mixture-of-Experts avec 671 milliards de paramètres et un contexte étendu à 128k tokens. Entraîné sur 14,8 milliers de milliards de tokens variés, ce modèle a placé DeepSeek au niveau des meilleurs modèles génériques, avec des performances comparables aux modèles fermés occidentaux tout en conservant un coût et une stabilité de formation remarquables.
- DeepSeek-V3 0324 – Mars 2025. Il s’agit de la version améliorée de V3 décrite dans cet article. Lancé officiellement le 25 mars 2025, V3 0324 apporte un saut qualitatif en raisonnement et en codage par rapport à V3. C’est également la première version V3 publiée directement sous licence MIT open source (les modèles V3 initiaux avaient une licence plus restrictive). Cette ouverture totale des poids du modèle devrait faciliter son adoption et ses contributions par la communauté.
Parallèlement à la série V (généralistes), DeepSeek a développé un axe spécialisé dans le raisonnement avancé. En janvier 2025, la start-up avait dévoilé DeepSeek-R1, un modèle dérivé de V3 mais affiné pour les chaînes de raisonnement complexes (Chain-of-Thought).
DeepSeek-R1 fut le premier modèle open source à rivaliser avec le modèle de raisonnement haut de gamme d’OpenAI (surnommé o1), réalisant des performances impressionnantes tout en coûtant moins de 6 millions $ à développer.
Le succès de R1 a été tel qu’il a brièvement entraîné un vent de panique sur les marchés : fin janvier, l’application DeepSeek Chat dépassait ChatGPT en tête de l’App Store, contribuant à une chute de 17 % de l’action Nvidia et à la remise en question des valorisations de plusieurs entreprises américaines de l’AI.
Fort de cette expérience, DeepSeek a incorporé certaines des innovations de R1 dans V3 0324 – par exemple des techniques de distillation de raisonnement issues de R1 ont été utilisées pour améliorer la capacité de V3 0324 à résoudre des problèmes complexes étape par étape.
Comparaison avec les modèles concurrents
Avec DeepSeek-V3 0324, la jeune pousse chinoise vise directement les modèles phares d’OpenAI, Anthropic, Google ou Meta.
D’après les évaluations, V3 0324 se hisse au niveau des modèles de chat les plus avancés comme ChatGPT (basé sur GPT-4) sur de nombreux points, tout en n’ayant coûté qu’une fraction de leur développement.
Par exemple, sur certains benchmarks de connaissances et de logique, le nouveau DeepSeek égale ou dépasse les scores de GPT-4.5 d’OpenAI ou de Claude 3.7 d’Anthropic.
En particulier, ses prouesses en mathématiques et en programmation lui permettent même de surpasser GPT-4.5 sur des tests spécialisés comme MATH-500 ou HumanEval, illustrant la compétitivité de cette solution open source face aux géants propriétaires.
Les autres modèles open source existants sont également éclipsés par DeepSeek-V3 0324 en termes de performances globales.
À ce jour, aucun modèle en accès libre n’affiche un tel niveau de résultats sur l’ensemble des domaines testés.
Cela positionne DeepSeek comme un leader de l’IA open source, aux côtés de quelques initiatives comparables de grandes entreprises chinoises (par ex. Alibaba a dévoilé son modèle Qwen 2.5 peu après) qui commencent à rivaliser avec les offres occidentales Le même jour que DeepSeek-V3 0324, Alibaba annonçait ainsi un nouveau modèle Apache 2.0, signe que la concurrence s’intensifie également entre acteurs chinois pour proposer des IA de pointe libres d’accès.
Il est important de noter que DeepSeek adopte une stratégie opposée à celle d’OpenAI sur plusieurs plans. Là où OpenAI garde ses meilleurs modèles (GPT-4, etc.) fermés et monétise l’accès via des API payantes, DeepSeek publie ses modèles en open source et gratuitement.
Cette approche bouscule le modèle économique des entreprises américaines : en offrant une performance équivalente sans coûts d’utilisation, DeepSeek menace de rendre obsolète la facturation à l’appel d’API pour certaines applications.
De plus, DeepSeek réussit cette prouesse malgré des contraintes technologiques – privé des puces les plus puissantes en raison des restrictions d’exportation américaines, il a dû se contenter de GPU H800 moins performants.
Le fait qu’un laboratoire chinois parvienne tout de même à atteindre l’état de l’art a été qualifié de véritable « moment Spoutnik » par des observateurs, en référence au choc du satellite soviétique dans la course à l’espace.
Cas d’usage et impact sur le marché de l’IA open source
Le modèle DeepSeek-V3 0324 étant disponible sous licence MIT, entreprises, chercheurs et développeurs du monde entier peuvent dès à présent l’exploiter, l’adapter ou l’intégrer à leurs projets sans entraves.
Ce niveau d’ouverture sur un modèle aussi avancé est inédit pour un modèle de cette ampleur.
Concrètement, DeepSeek-V3 0324 peut servir de base à des assistants conversationnels ou chatbots personnalisés, sans dépendre d’une infrastructure cloud propriétaire.
Les organisations disposant de ressources GPU suffisantes peuvent héberger le modèle et l’utiliser pour de la génération de texte, du résumé de documents volumineux (grâce à sa fenêtre contextuelle de 128k tokens), ou encore comme aide à la programmation.
En effet, l’une des cibles de DeepSeek est le développement logiciel : le modèle a démontré une capacité à générer du code exécutable (HTML/JS/CSS) avec un rendu plus propre et esthétique pour des pages web ou des interfaces de jeu.
Cette compétence en fait un outil potentiel pour les développeurs front-end souhaitant accélérer la création de prototypes ou de sites web.
DeepSeek-V3 0324 se distingue également par son excellence en langue chinoise, ce qui n’est pas surprenant venant d’une start-up basée à Hangzhou.
Le modèle a bénéficié d’améliorations spécifiques pour produire des textes en chinois de meilleure qualité stylistique et cohérents sur de longues pages Il est par exemple capable de rédiger des documents complexes en chinois, de traduire ou de reformuler du texte tout en respectant un certain style (notamment en s’alignant sur le style d’écriture de la série R1, selon DeepSeek). Ces atouts le destinent naturellement au vaste marché sinophone, que ce soit pour des assistants virtuels, des outils d’écriture intelligente ou des services de recherche en langue locale.
Néanmoins, ses compétences ne se limitent pas au chinois : DeepSeek-V3 0324 figure parmi les meilleurs modèles non-spécialisés en raisonnement sur le benchmark Polyglot (55 % de réussite), montrant une polyvalence dans plusieurs langues.
Par ailleurs, DeepSeek a intégré dans V3 0324 des fonctions avancées pour interagir avec des outils externes.
Le modèle supporte nativement le « Function Calling », c’est-à-dire la capacité pour l’IA d’appeler des fonctions ou API tierces de manière contrôlée afin de réaliser des actions (chercher une information, effectuer un calcul, etc.).
Les développeurs pourront donc s’en servir comme cerveau d’agents logiciels autonomes (AI assistants) capables de combiner conversation et actions programmatiques.
DeepSeek indique avoir amélioré la précision de ces appels de fonction dans la nouvelle version, corrigeant les erreurs observées dans V3 initial.
Cela ouvre la porte à des cas d’usage agentiques plus fiables – par exemple un assistant personnel qui répond aux questions de l’utilisateur et peut en parallèle aller consulter le web ou contrôler des appareils connectés sur commande.
En termes d’impact sur le marché, le lancement de DeepSeek-V3 0324 est perçu comme un accélérateur pour l’écosystème IA open source.
D’une part, il fournit à la communauté un modèle de pointe librement accessible, ce qui va stimuler la recherche et les expérimentations (on peut s’attendre à des travaux de fine-tuning, d’optimisation et des variantes spécialisées issues de V3 0324).
D’autre part, il met la pression sur les entreprises établies : face à une alternative gratuite et performante, les clients pourraient se montrer moins enclins à payer pour des solutions propriétaires coûteuses.
Il n’est pas anodin que quelques jours seulement après cette sortie, OpenAI ait évoqué de nouvelles améliorations à venir sur ses propres modèles, et que des acteurs comme Microsoft ou Anthropic soulignent la valeur ajoutée de leurs écosystèmes fermés en matière de sécurité ou de support – signes que la concurrence s’adapte à cette montée en puissance de l’open source.
Enfin, sur le plan géopolitique et industriel, l’ascension de DeepSeek illustre le rattrapage de la Chine dans la course à l’IA.
En l’espace de quelques mois, des startups chinoises ont proposé une dizaine de modèles de langue de haut niveau, dont plusieurs open source, remettant en question la domination technologique américaine.
La réussite de DeepSeek, soutenue par des fonds privés chinois (notamment le hedge fund High-Flyer), montre qu’une innovation agile et frugale est possible dans le domaine de l’IA de pointe.
Cela incite les acteurs du secteur à travers le monde à repenser leurs stratégies – entre ouverture du code, optimisation des coûts et collaboration internationale – pour ne pas se laisser distancer.
Le modèle DeepSeek-V3 0324, en combinant hautes performances, open source et faible coût, pourrait ainsi marquer un tournant dans le monde de l’intelligence artificielle, en démocratisant encore davantage l’accès aux capacités avancées et en élargissant le champ des possibles pour les utilisateurs comme pour les développeurs


