
DeepSeek V3.2-Exp est une version expérimentale publiée en septembre 2025. Elle a ensuite été remplacée dans les services officiels par DeepSeek-V3.2, désormais mis en avant sur l’app, le web et l’API.
Sans bouleverser l’architecture fondamentale (Mixture-of-Experts massif d’environ 671 milliards de paramètres), V3.2-Exp apporte de nouvelles fonctionnalités clés : un mécanisme d’attention sparse ultra-efficient, la prise en charge de prompts multimodaux, des outils intégrés avancés, des modes de raisonnement ajustables, ainsi qu’une compatibilité accrue avec l’API et les frameworks existants.
Le tout en restant open-source et 50 % moins coûteux à utiliser que la version précédente.
Dans cet article technique, nous explorons en détail ces nouveautés et comment les exploiter, avec exemples concrets à l’appui.
Prompts multimodaux et contexte étendu
DeepSeek V3.2-Exp a surtout été présenté comme un modèle expérimental orienté efficacité, contexte long et capacités agentiques. DeepSeek V3.2‑Exp est présenté ici comme une étape expérimentale historique. Les capacités image ou audio ne sont mentionnées que lorsqu’elles sont confirmées par une documentation officielle actuelle.
Par exemple, via l’interface Chat DeepSeek, il est possible de fournir une image ou un fichier audio en entrée : le système en extrait le contenu pertinent (description d’image, transcription audio, etc.) et l’intègre dans le prompt pour le traitement. Cette faculté donne aux développeurs la possibilité de créer des assistants capables d’analyser des documents visuels ou sonores en plus du texte.
Essentiellement, DeepSeek V3.2-Exp peut extraire des informations clés d’une image, transcrire un fichier audio et synthétiser un texte, le tout dans un même flux de travail.
En parallèle, V3.2-Exp conserve et optimise la gestion de contextes ultra-longs. Avec une fenêtre de contexte pouvant atteindre 128 000 tokens, il excelle dans l’analyse de documents volumineux ou de longues conversations.
La nouveauté, c’est que le modèle peut exploiter cette longueur maximale de façon bien plus efficiente qu’auparavant grâce à son mécanisme d’attention sparse (voir section suivante).
Pour le développeur, cela signifie qu’il est envisageable d’alimenter l’IA avec des dizaines de pages de documentation ou de code en un seul prompt, sans explosion du temps de calcul ni des coûts.
Des optimisations côté API, comme la mise en cache de segments répétés, permettent même de réduire le coût de traitement sur les contextes réutilisés – en pratique, du contenu déjà analysé peut être mis en cache pour éviter de le facturer à nouveau (cache hit facturé ~$0.07/M tokens vs ~$0.56 en temps normal).
En somme, DeepSeek V3.2-Exp est taillé pour les applications nécessitant de très larges contextes (lecture de corpus entiers, agrégation de multiples sources, etc.), avec un coût par token fortement diminué.
Exemple d’usage : un assistant documentaire intelligent capable de digérer un manuel technique de 1000 pages en une requête devient envisageable.
Le développeur peut fournir le PDF entier en entrée (converti en texte) et poser des questions pointues ; DeepSeek V3.2-Exp trouvera les segments pertinents grâce à son attention optimisée et renverra des réponses précises, le tout sans dépassement de temps ni coût prohibitif.
De même, pour un chatbot support client, on peut charger une base de connaissances volumineuse en contexte : le modèle pourra y puiser des informations exactes sur 100 000+ tokens de texte, offrant un support détaillé en langage naturel.
Attention clairsemée (DSA) : efficacité sur les longs contextes
La DeepSeek Sparse Attention (DSA) est l’amélioration technique phare introduite dans V3.2-Exp.
Ce mécanisme d’attention « clairsemée » repense la façon dont le modèle se concentre sur les tokens d’entrée, afin de gagner en efficacité lorsque le contexte est très long.
Plutôt que de calculer l’attention entre chaque paire de tokens (coût quadratique O(n²) qui explose vite sur de grosses entrées), le modèle sélectionne intelligemment les positions réellement pertinentes à considérer pour chaque token.
En pratique, cela signifie qu’au sein d’une séquence de, par exemple, 100 000 tokens, chaque token ne prêtera attention qu’à un sous-ensemble restreint de tokens utiles, au lieu d’itérer sur les 99 999 autres.
Concrètement, DSA réduit drastiquement les calculs inutiles sur les séquences longues en n’accordant une attention fine qu’aux segments pertinents plutôt qu’à l’entièreté du texte.
Le modèle identifie dynamiquement les portions importantes du contexte au fil du traitement, au lieu d’appliquer un schéma fixe.
Résultat : beaucoup moins d’opérations à effectuer, pour un rendement quasiment identique en termes de compréhension globale.
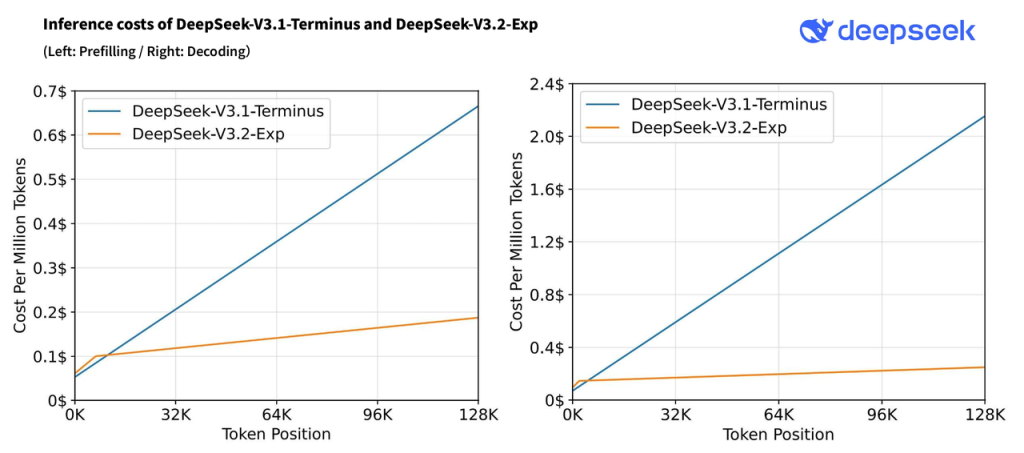
Les ingénieurs de DeepSeek rapportent ainsi des gains de vitesse de l’ordre de ×2 à ×3 sur l’inférence de textes très longs, tout en consommant ~30 à 40 % de mémoire GPU en moins, et cela sans aucune dégradation notable de la qualité des réponses.
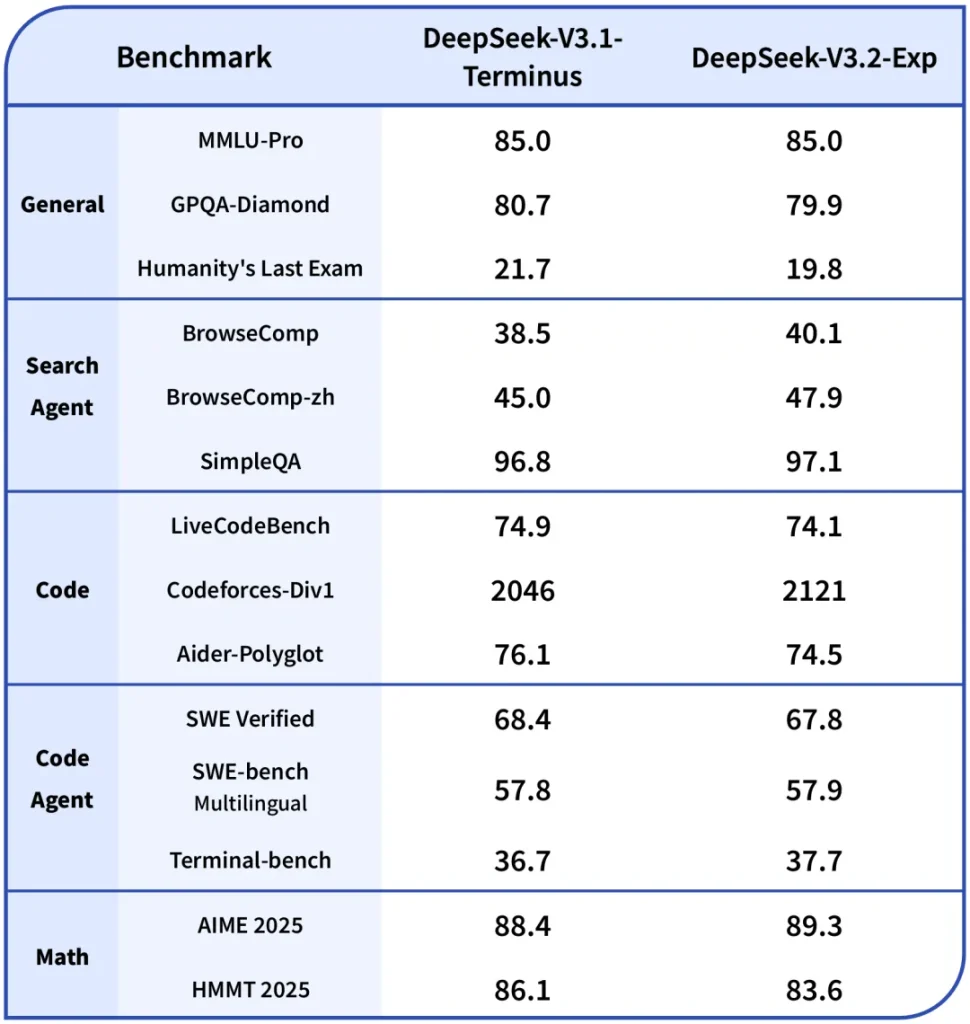
Autrement dit, les performances mesurées de V3.2-Exp sur des benchmarks variés restent au niveau de V3.1-Terminus, mais obtenues avec une efficience bien supérieure.
D’un point de vue développeur, l’attention sparse apporte un double bénéfice : rapidité et économie.
Les appels API traitant de gros prompts renvoient des réponses plus vite, et la facturation (qui dépend du nombre de tokens traités) s’en trouve allégée.
Dans la pratique, DeepSeek a pu baisser le tarif de son API de plus de 50 % grâce à DSA, rendant l’accès au modèle beaucoup plus abordable.
Techniquement, cette avancée ouvre la porte à de nouvelles applications auparavant limitées par le coût du long contexte (ex : fouille de données dans des archives, analyse juridique sur des milliers de pages, IA conversationnelle ayant une mémoire étendue sur d’innombrables échanges).
Exemple d’usage : imaginez un agent analytique qui épluche automatiquement des rapports financiers annuels de 500 pages chacun pour en extraire des indicateurs – avec V3.2-Exp, on peut fournir l’intégralité de chaque rapport en entrée et obtenir un résumé ou des données calculées très rapidement.
Grâce à DSA, le modèle ne « lit » en profondeur que les sections pertinentes (p. ex. les tableaux comptables, les sections ciblées par la question) et ignore le reste, ce qui lui permet de répondre en quelques secondes là où un modèle classique saturerait ou mettrait une minute.
Le développeur bénéficie ainsi d’une scalabilité accrue : intégrer l’IA à des flux de travail sur de la donnée volumineuse (analyse de big data textuel, veille d’articles scientifiques, etc.) devient plus simple et moins onéreux.
Modes de raisonnement ajustables (Think & Non-Think)
DeepSeek V3.2-Exp reprend et consolide le concept de modes de raisonnement introduit avec V3.1. Le modèle peut fonctionner selon deux modes distincts au choix du développeur : un mode « non-thinking » (réponse directe) et un mode « thinking » (raisonnement pas à pas).
Dans le premier, l’IA fournit immédiatement la réponse finale concise, idéale pour la majorité des requêtes simples ou pour un usage conversationnel rapide. Dans le second, l’IA génère d’abord une réflexion détaillée – une suite d’étapes logiques, calculs ou déductions – avant de livrer la conclusion.
Ce « chain-of-thought » explicite améliore considérablement la performance sur les problèmes complexes ou multi-étapes (problèmes mathématiques, code à débugger, planification, etc.), car le modèle pense à voix haute et évite d’omettre des sous-étapes de raisonnement.
Techniquement, ces deux modes sont implémentés via deux points d’entrée du modèle : deepseek-chat pour le mode normal, et deepseek-reasoner pour le mode raisonneur. Sous le capot, ils s’appuient sur le même modèle V3.2-Exp, mais configuré différemment.
En mode raisonneur, le modèle est autorisé à produire une grande quantité de tokens « d’explication » interne (jusqu’à 32 000 tokens de raisonnement intermédiaire par défaut) avant de répondre. En revanche, certains paramètres aléatoires comme la température ou le top_p sont désactivés pour garantir une cohérence du raisonnement.
Le résultat est que le développeur peut choisir, pour une requête donnée, le niveau de transparence du processus de l’IA.
Exemple d’usage : un développeur crée un outil d’aide à la résolution de problèmes de code. En mode normal, DeepSeek V3.2-Exp renvoie directement le correctif ou l’explication du bug.
En mode « thinking », il détaillera ligne par ligne son analyse du code, les erreurs trouvées, les étapes pour les corriger, puis proposera la solution finale.
Ce mode raisonneur peut aussi servir en phase de débogage de prompts : en demandant au modèle d’exposer sa logique, on peut mieux comprendre pourquoi il donne telle réponse et ajuster nos instructions.
Notez que l’API officielle DeepSeek ne renvoie pas encore le raisonnement intermédiaire dans sa réponse finale (ceci reste expérimental), mais des intégrations tierces comme LangChain le supportent déjà.
Quoi qu’il en soit, la présence de ces deux modes au sein d’un même modèle unifié est un atout pratique : pas besoin de changer de modèle pour alterner entre réponses rapides et réflexion approfondie.
Outils avancés et intelligence agentique
Une autre avancée majeure de DeepSeek V3.2-Exp concerne son intégration d’outils externes et ses capacités « agentiques ».
Le modèle a été entraîné et optimisé pour utiliser des outils – c’est-à-dire appeler des fonctions ou services externes – afin d’accomplir des tâches plus complexes que la simple génération de texte. En pratique, cela signifie que V3.2-Exp sait par exemple déclencher une recherche web, interroger une base de données, appeler une API de calcul ou exécuter du code, dans le cadre d’un prompt structuré.
DeepSeek avait déjà introduit des appels de fonction structurés (format JSON) et le support de plugins dans ses versions précédentes, mais V3.2-Exp pousse encore plus loin cette approche.
Grâce à un finetuning spécialisé post-entraînement, le modèle comprend mieux quand et comment utiliser un outil pour trouver une réponse.
Par exemple, sur les benchmarks évaluant l’utilisation d’un navigateur web (BrowseComp), V3.2-Exp surpasse les itérations antérieures en réussissant plus souvent à employer correctement l’outil de recherche pour trouver des informations. En interne, le mode raisonneur s’avère particulièrement utile pour ces agents : le modèle peut d’abord élaborer un plan d’actions (ex. « Étape 1 : chercher tel mot-clé sur le web ; Étape 2 : lire le résultat ») avant d’invoquer successivement les outils requis.
DeepSeek V3.2-Exp a montré des améliorations notables dans ce cadre, le rendant apte à servir de cerveau pour agents autonomes multi-étapes.
Pour les développeurs, cela ouvre la porte à des applications de type GPT-4 Plugins ou AutoGPT, mais en open-source.
On peut construire un assistant capable non seulement de répondre, mais d’agir : par exemple, réserver un billet en appelant une API, parcourir une documentation via un navigateur intégré, ou encore exécuter du code Python pour vérifier un résultat. DeepSeek V3.2-Exp supporte nativement le format d’appel de fonction introduit par OpenAI (JSON décrivant la fonction à appeler et ses arguments), ce qui facilite grandement la mise en place de ces interactions.
De plus, des projets comme LangChain, AWX ou d’autres frameworks d’agents ont intégré DeepSeek en tant que LLM « outillé », ce qui signifie qu’un développeur peut plugger V3.2-Exp dans une architecture d’agent existante sans friction.
Exemple d’usage : une startup développe un assistant DevOps autonome. En langage naturel, on demande « Déploie-moi une instance serveur avec telle config sur AWS ».
L’agent, propulsé par DeepSeek V3.2-Exp, va comprendre la demande, générer un plan (créer une instance EC2, configurer la sécurité, déployer l’application…), puis appeler successivement les outils/API AWS correspondants pour réaliser chaque étape.
Le modèle gère la logique et la prise de décision, en s’appuyant sur ses capacités de raisonnement et la possibilité d’utiliser des plugins (AWS SDK, etc.).
Ce type d’agent, qui réfléchit et agit, bénéficie directement des optimisations de V3.2-Exp en matière de tool use et de contexte long (il peut conserver l’historique de ses actions sur des milliers de tokens si besoin).
Optimisations internes et configuration du modèle expérimental
En coulisses, DeepSeek V3.2-Exp embarque plusieurs améliorations internes notables qui intéresseront les développeurs cherchant à auto-héberger ou à personnaliser le modèle.
D’abord, il convient de rappeler que DeepSeek V3 est basé sur une architecture Mixture-of-Experts (MoE). Concrètement, le modèle global compte 671 milliards de paramètres au total, répartis en de nombreux experts, mais seuls ~37 milliards sont activés pour un token donné.
Cela lui permet d’atteindre une qualité comparable à des modèles géants tout en limitant les besoins de calcul par token. La version 3.2-Exp conserve cette architecture colossale (685B paramètres annoncés côté DeepSeek) mais a bénéficié de nouvelles optimisations lors de l’entraînement.
Notamment, DeepSeek a été pionnier dans l’utilisation de la précision flottante 8-bit (FP8) pour l’entraînement de modèles géants, et continue d’exploiter cette approche en inférence. Le modèle est donc compatible avec des runtimes quantifiés (INT8/FP8) sans perte significative de précision, ce qui réduit encore son empreinte en production.
Pour les développeurs, cela signifie qu’il est possible d’exécuter V3.2-Exp en mode 8-bit sur du matériel supporté, et ainsi de diviser la mémoire requise par deux et d’accélérer les calculs.
Par ailleurs, V3.2-Exp a été conçu pour être polyvalent en termes d’infrastructure. DeepSeek a publié dès la sortie du modèle des optimisations spécifiques pour divers hardware.
Par exemple, des kernels d’inférence optimisés ont été fournis pour les GPU Nvidia (CUDA), mais aussi pour les processeurs d’IA Huawei Ascend (via le framework CANN) et pour les NPUs Cambricon.
En moins de 24h après le lancement, la communauté a intégré le support de V3.2-Exp sur des plateformes comme vLLM (y compris une version adaptée aux accélérateurs Ascend).
En pratique, si vous disposez d’une machine multi-GPU ou même de matériel exotique, il y a de fortes chances que des conteneurs Docker ou des scripts existent déjà pour déployer DeepSeek V3.2-Exp efficacement.
Côté configuration logicielle, le modèle reste entièrement open-source et modifiable. Le dépôt officiel propose un fichier de configuration JSON détaillant l’architecture (par ex. config_671B_v3.2.json), ce qui permet de l’ajuster ou de l’utiliser dans des serveurs d’inférence personnalisés.
Les développeurs curieux peuvent également explorer le code source des kernels implémentant l’attention sparse et d’autres composants (écrit en TileLang et CUDA) mis à disposition pour la recherche reproductible.
Cette transparence est précieuse : elle permet de comprendre finement le fonctionnement interne de V3.2-Exp, voire de modifier certains hyperparamètres pour des besoins spécifiques (par exemple, changer le nombre d’« experts » MoE utilisés si l’on souhaite réduire le modèle pour des tests, ou ajuster les limites de génération du mode raisonneur).
En termes de fine-tuning, le fait que les poids du modèle soient publiés sous licence MIT offre la possibilité d’un entraînement supplémentaire sur des données spécialisées.
Bien qu’en pratique fine-tuner un modèle de 671B paramètres soit un chantier lourd, des approches plus légères comme le Low-Rank Adaptation (LoRA) peuvent être employées pour adapter V3.2-Exp à un domaine pointu en n’entraînant qu’une petite portion de paramètres.
Par exemple, on pourrait affiner le modèle sur du jargon médical ou juridique pour le rendre encore plus performant dans ces domaines. Quelques précautions s’imposent toutefois : le format MoE nécessite de bien comprendre la répartition des experts, et l’attention sparse modifie légèrement les dynamiques d’entraînement.
Néanmoins, la communauté open-source s’est déjà emparée de V3.2-Exp et partage des retours sur ce terrain, ce qui augure d’extensions innovantes via fine-tuning dans un futur proche.
Compatibilité API et intégration simplifiée
Du point de vue de l’intégration dans les applications, DeepSeek V3.2-Exp a été pensé pour faciliter la vie des développeurs. Tout d’abord, son API est hautement compatible avec l’API OpenAI.
Si vous avez déjà utilisé le SDK OpenAI (par exemple pour GPT-3/4), vous pouvez appeler DeepSeek V3.2-Exp de manière quasi identique – mêmes formats de requêtes et de réponses.
En pratique, DeepSeek fournit un endpoint chat-completion où il suffit de spécifier le nom du modèle ("deepseek-chat" ou "deepseek-reasoner") et d’envoyer la liste des messages (system/user/assistant) comme on le ferait avec ChatGPT. Le modèle respecte également les clés de paramètres usuelles (temperature, max_tokens, etc., à l’exception de certaines qui sont désactivées en mode raisonneur).
Cette compatibilité API réduit drastiquement le coût de transition pour intégrer DeepSeek dans une application existante : souvent, quelques lignes de configuration suffisent pour passer d’OpenAI à DeepSeek.
En plus de l’API cloud V3.2-Exp s’insère bien dans l’écosystème open-source. Sur Hugging Face, les poids du modèle sont disponibles librement, et un script de conversion permet de les charger dans l’architecture Tensor Parallelism de DeepSeek.
Des démos d’inférence en local sont fournies (notamment une interface CLI/Chat à lancer avec PyTorch).
Pour déployer le modèle en production, plusieurs solutions existent dès le jour du lancement : par exemple, vLLM supporte V3.2-Exp nativement, offrant un serveur haute performance prêt à l’emploi.
Il existe également des images Docker optimisées (via SGLang) pour les GPUs Nvidia H100, les GPUs AMD MI250/300, et même pour des NPUs dédiés.
En clair, que vous souhaitiez utiliser DeepSeek via le cloud ou sur votre propre infrastructure, les outils sont là.

Integrer DeepSeek V3.2-Exp avec des solutions tierces est tout aussi aisé.
Par exemple, pour les adeptes d’AWS, le modèle est disponible via Amazon Bedrock, ce qui permet de l’appeler directement depuis un environnement AWS (Lambda, SageMaker…) sans avoir à gérer l’infrastructure de l’IA.
Des notebooks d’exemple fournis par AWS montrent comment utiliser DeepSeek dans des cas concrets (chatbot, assistant de code, etc.). De même, des frameworks comme LangChain ont ajouté le support de DeepSeek V3 (y compris le mode raisonneur) dans leurs modules de LLMs, facilitant la création d’applications complexes (agents de recherche, chaînes de réflexion multi-appels, etc.) en quelques lignes de Python.
Enfin, la communauté open-source fournit régulièrement des recettes d’intégration pour d’autres plateformes (Kubernetes, serveurs web, mobiles, etc.) pour tirer parti de ce modèle à 671B paramètres dans divers contextes.
Cas d’usage concrets pour les développeurs
Pour illustrer la valeur de DeepSeek V3.2-Exp dans des projets de développement IA, voici quelques cas d’utilisation concrets rendus possibles (ou grandement facilités) par les nouveautés de cette version :
- Analyse de documents massifs : grâce à DSA et au contexte 128K, un développeur peut créer un assistant capable de lire et résumer de gigantesques documents. Par exemple, une application de recherche juridique peut ingérer l’ensemble d’un dossier de jurisprudence (des dizaines de documents totalisant 100K tokens) et permettre des questions en langage naturel. V3.2-Exp filtrera efficacement le contexte pour ne retenir que les passages pertinents et fournir des réponses argumentées, le tout en restant rapide et peu coûteux.
- Agent conversationnel outillé : en combinant le mode raisonneur et le support d’outils avancés, on peut développer un agent autonome qui interagit avec son environnement. Par exemple, un bot de support IT qui non seulement explique une procédure, mais exécute des actions (vérifier l’état d’un serveur, redémarrer un service via API, etc.). DeepSeek V3.2-Exp planifie la solution étape par étape (mode thinking) et utilise des appels de fonction pour accomplir chaque tâche. Cela simplifie énormément la logique côté développeur : on laisse l’IA orchestrer les appels outillés de manière cohérente.
- Assistant de programmation augmenté : avec les capacités de chain-of-thought et le contexte long, un IDE intelligent alimenté par V3.2-Exp peut maintenir en mémoire l’intégralité d’un projet volumineux et aider au debug. Un développeur peut demander « Trouve les erreurs potentielles dans ce repo et corrige-les » : le modèle examinera de nombreux fichiers (contexte long), identifiera les bugs en suivant un raisonnement structuré, et éventuellement proposera un patch. S’il a besoin de tester un code, il peut même exécuter un snippet via un outil sandbox intégré. On obtient un pair programmer IA ultra performant, capable de naviguer dans de grandes bases de code.
- Traduction et génération multimodale : profitant de l’aspect multimodal, on peut concevoir un service où l’utilisateur fournit par exemple une image contenant du texte (photo d’un document) et demande sa traduction en français. DeepSeek V3.2-Exp, couplé à un module OCR en amont (pour extraire le texte de l’image), traitera ensuite la traduction du contenu textuel détecté. De même, un outil de synthèse de rapports pourrait accepter en entrée une vidéo de conférence (transcrite via un modèle audio) et des documents PDF, puis résumer le tout de façon unifiée. La capacité de DeepSeek à digérer des entrées hétérogènes en fait un hub central pour ce type de workflow multimodal.
- Applications multi-langues et locales : enfin, le fait que DeepSeek V3.2-Exp soit open-source et adaptable le rend intéressant pour des solutions on-premise nécessitant une personnalisation locale (données privées, langues rares, etc.). Un organisme public pourrait, par exemple, fine-tuner le modèle sur ses documents internes en langue locale et déployer l’IA en interne, évitant d’exposer ses données à des services cloud tiers. La compatibilité avec divers matériels (GPU, NPU…) et la licence permissive offrent une flexibilité totale pour intégrer l’IA là où on en a besoin, sans dépendre d’un fournisseur unique.
Essayez DeepSeek V3.2-Exp dès maintenant
DeepSeek V3.2-Exp représente une étape expérimentale importante dans l’évolution des modèles DeepSeek. Cette version a permis d’explorer de nouvelles approches en matière de raisonnement et d’efficacité, avant l’introduction de versions plus stables mises en avant par DeepSeek.
Pour en comprendre pleinement l’intérêt, il est recommandé de le considérer comme une version de transition dans la feuille de route du projet, plutôt que comme un modèle actuellement déployé à grande échelle.
Si vous souhaitez tester les capacités actuelles des modèles DeepSeek, vous pouvez utiliser deepseek-fr.ai, une interface indépendante non affiliée à DeepSeek, qui permet d’interagir avec des modèles DeepSeek directement depuis le navigateur, sans inscription.
Pour suivre les versions réellement disponibles, les évolutions techniques et les changements officiels, il reste préférable de consulter la documentation officielle de DeepSeek ainsi que ses canaux publics destinés aux développeurs.
Ainsi, DeepSeek V3.2-Exp reste surtout utile pour comprendre la progression technologique du projet, et non comme une version principale actuellement mise en avant.


