
DeepSeek R1 est un jalon important du raisonnement chez DeepSeek. Cette fiche doit être lue comme une page de contexte historique ; pour l’usage actuel, référez-vous d’abord au modèle officiellement en production et au changelog de l’API DeepSeek.
Ses poids et son code source sont publiés sous licence MIT, ce qui en fait un modèle de langage IA gratuit librement utilisable (y compris commercialement) et modifiable par la communauté.
L’objectif affiché de DeepSeek R1 est de démocratiser l’accès à une IA puissante axée sur le raisonnement, en offrant des performances de pointe tout en étant accessible en open source.
Présentation générale de DeepSeek R1
DeepSeek R1 est présenté comme un modèle de langage avancé capable d’effectuer les mêmes tâches textuelles que les meilleurs modèles propriétaires, tout en étant open source et optimisé pour un usage développeur.
Développé par la société DeepSeek (fondée en 2023), il s’intègre dans la lignée d’une série de modèles open source publiés par cette entreprise.
Son lancement début 2025 a marqué une avancée notable de la communauté IA open source, en montrant qu’un modèle libre pouvait atteindre un niveau de performance jusqu’alors réservé à des modèles fermés très coûteux.
DeepSeek R1 est spécialement orienté vers les tâches de raisonnement complexe, avec une emphase sur la résolution de problèmes mathématiques, le codage, l’inférence logique et les autres domaines nécessitant une réflexion structurée.
DeepSeek R1 est une famille de modèles de raisonnement publiée début 2025. À la date du 19 mars 2026, les services officiels récents mettent surtout en avant DeepSeek-V3.2 et ses modes thinking/non-thinking ; présentez donc R1 comme une étape majeure de l’évolution du raisonnement chez DeepSeek.
Le modèle est disponible en open source depuis son lancement, accompagné d’un rapport technique détaillé, ce qui permet à tout développeur d’examiner son fonctionnement, de l’utiliser dans ses propres projets ou de le personnaliser librement.

Architecture du modèle
Du point de vue technique, DeepSeek R1 est construit sur une architecture de transformeur moderne intégrant une conception Mixture-of-Experts (MoE). Cela signifie que le modèle comprend de multiples “experts” spécialisés activés dynamiquement en fonction de la requête.
Concrètement, DeepSeek R1 possède un total colossal d’environ 671 milliards de paramètres, mais seulement ~37 milliards d’entre eux sont activés pour un prompt donné.
Cette approche MoE lui permet d’atteindre la puissance d’un modèle géant tout en maîtrisant les coûts de calcul, puisque le modèle n’utilise qu’une fraction de ses paramètres à chaque requête (focalisant sur les experts pertinents).
En pratique, DeepSeek R1 peut ainsi mobiliser des paramètres spécialisés sur des tâches particulières sans sacrifier l’efficacité globale.
Autre caractéristique majeure de l’architecture : une fenêtre de contexte extrêmement large. DeepSeek R1 prend en charge des contextes allant jusqu’à 128 000 tokens (128k), soit l’équivalent d’un petit livre en entrée.
Cette longueur de contexte dépasse de loin celle des LLM habituels et permet au modèle de traiter et “se souvenir” d’énormes volumes d’information au sein d’une même requête.
Par exemple, R1 peut analyser intégralement un long document, un ensemble de fichiers code source volumineux ou mener une conversation sur des centaines de pages de texte sans perdre le fil.
Cela le dote d’une capacité unique pour la compréhension de textes longs, évitant d’avoir à segmenter l’entrée en morceaux plus petits.
En termes d’entraînement, DeepSeek R1 se distingue également par sa pipeline d’apprentissage centrée sur le renforcement.
Il a été développé à partir d’un modèle de base (DeepSeek V3) en appliquant une série d’étapes d’apprentissage par renforcement (RL) à grande échelle, avec un minimum d’ajustement supervisé initial.
Une version préliminaire nommée DeepSeek-R1-Zero a d’abord été entraînée uniquement via RL, ce qui lui a permis d’acquérir spontanément des comportements de raisonnement puissants (capacité à se corriger, à réfléchir de manière itérative, à produire de longues chaînes de raisonnement).
Cependant, cette version RL-only souffrait de certains défauts (tendance à la répétition, baisse de lisibilité, mélange non désiré de langues).
Pour y remédier, les auteurs ont introduit dans DeepSeek R1 final un apport de données d’amorçage (“cold-start”) et quelques phases de fine-tuning supervisé pour stabiliser le langage et aligner le modèle sur les préférences humaines.
Le pipeline complet comporte deux phases de RL (pour pousser plus loin les schémas de raisonnement et aligner les réponses) intercalées de phases de fine-tuning supervisé, afin d’obtenir un modèle à la fois excellent en raisonnement et polyvalent sur des tâches plus générales.
En résumé, l’architecture de DeepSeek R1 allie échelle massive (MoE 671B) et entraîneur spécialisé (RL pour le chain-of-thought), ce qui aboutit à un modèle capable de “penser” en plusieurs étapes pour résoudre des problèmes complexes.
Taille du modèle et ses variantes
Le modèle DeepSeek R1 lui-même représente la configuration la plus puissante de la série, avec 671 milliards de paramètres totaux (dont ~37B activés par requête) et une fenêtre de contexte de 128k tokens comme indiqué plus haut.
Il s’agit d’un modèle très grand, pensé pour tourner sur une infrastructure multi-GPU ou serveur haute performance.
Conscient que peu d’équipes peuvent exécuter localement un modèle de cette taille, DeepSeek a également publié toute une gamme de versions allégées par distillation, afin de rendre sa technologie accessible sur du matériel plus modeste.
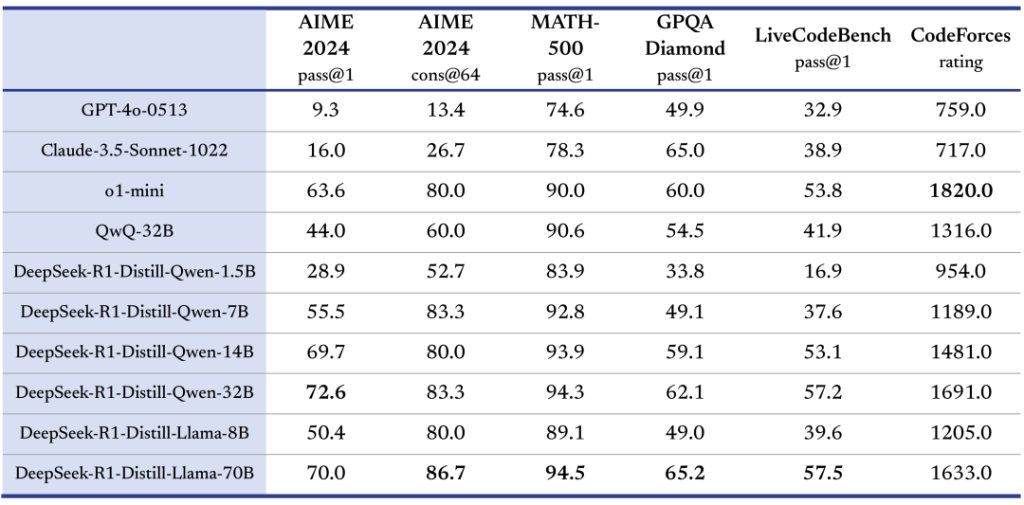
Au total, six modèles distillés de plus petite taille ont été open-source aux côtés de R1. Ces modèles “DeepSeek-R1-Distill” ont des nombres de paramètres bien inférieurs, allant d’environ 1,5 milliard jusqu’à 70 milliards de paramètres, ce qui couvre une gamme de puissances adaptée à divers cas d’usage et contraintes hardware. Plus précisément :
- DeepSeek-R1-Zero – ~671B (identique à R1 en taille, version entraînée RL seul, surtout d’intérêt pour la recherche).
- DeepSeek-R1 (standard) – ~671B (modèle principal décrit dans cet article).
- Modèles distillés denses dérivés de R1 :
- 1,5B de paramètres (variante basée sur Qwen 2.5) – très légère, tournant sur GPU grand public (idéal pour tests ou intégration embarquée).
- 7B de paramètres (basé Qwen 2.5) – tient sur un seul GPU 16Go, offrant déjà des capacités notables de R1 en version compacte.
- 8B de paramètres (basé Llama 3.1) – équivalent à d’autres LLM 8B, utile pour expérimenter l’ADN de R1 sur du matériel réduit.
- 14B de paramètres (Qwen 2.5) – une taille intermédiaire, encore exécutable sur un GPU haut de gamme.
- 32B de paramètres (Qwen 2.5) – commence à nécessiter plusieurs GPU ou beaucoup de VRAM, mais fournit une performance proche du modèle complet sur de nombreuses tâches.
- 70B de paramètres (Llama 3.3 instruct) – le plus grand modèle distillé, approchant l’état de l’art dense tout en restant beaucoup plus facile à déployer que 671B.
Toutes ces variantes distillées héritent en partie des capacités de raisonnement de DeepSeek R1, car elles ont été fine-tunées sur des exemples de chaînes de raisonnement générés par R1 lui-même.
Elles obtiennent ainsi des performances remarquables sur les benchmarks, souvent supérieures aux modèles de base dont elles sont issues, tout en pouvant être exécutées sur des configurations matérielles bien plus accessibles.
Par exemple, DeepSeek indique que son modèle distillé de 32B rivalise avec des modèles propriétaires plus grands sur des tâches de raisonnement, tout en pouvant tourner sur un serveur bi-GPU standard.
En open-sourçant ces multiples versions, DeepSeek R1 s’adapte aux besoins variés des développeurs : du simple LLM open source pour développeur individuel (avec la version 7B ou 14B sur une carte graphique grand public) jusqu’à la solution IA haut de gamme (version complète 671B) pour les entreprises qui peuvent mobiliser une grappe de GPUs.
Corpus d’entraînement et distribution linguistique
Le corpus d’entraînement de DeepSeek R1 est très vaste et diversifié, reflétant son ambition de servir de modèle généraliste orienté raisonnement.
La base de données utilisée combine de gigantesques volumes de texte web, des documents techniques (par ex. articles scientifiques, manuels) ainsi que du code source provenant de dépôts open source.
L’équipe de DeepSeek a mis l’accent sur la qualité et la diversité des données : de robustes filtrages ont été appliqués pour éliminer le contenu bruité ou redondant, et le tokeniseur du modèle a été optimisé aussi bien pour le multilingue que pour la syntaxe du code (vocabulaire adapté aux langages de programmation).
En outre, une stratégie d’échantillonnage pondérée a permis de sur-représenter certains domaines pointus (textes scientifiques, langages de programmation moins courants) afin d’améliorer la couverture de ces sujets pendant l’apprentissage.
Sur le plan linguistique, DeepSeek R1 est un modèle multilingue mais fortement optimisé pour l’anglais et le chinois. En effet, le modèle de base utilisé (DeepSeek V3) a été principalement entraîné sur plusieurs langues avec une proportion très importante d’anglais et de chinois.
De ce fait, R1 excelle naturellement dans ces deux langues – il est capable de mener des conversations cohérentes en anglais ou en chinois, de comprendre des questions complexes dans ces langues et d’y répondre avec précision.
En revanche, lorsque le modèle est sollicité dans d’autres langues moins représentées dans son entraînement, il peut présenter des mélanges de langue ou une dégradation de la qualité de réponse.
Les développeurs ont constaté par exemple qu’une question posée en français ou en espagnol pourrait amener R1 à répondre partiellement en anglais (ou en chinois), faute d’une assurance suffisante dans la langue cible.
Ainsi, pour un usage optimal, il est recommandé d’utiliser principalement l’anglais ou le chinois dans les requêtes, ou de bien surveiller la sortie si l’on interroge le modèle en langue tierce.
Concernant les langages de programmation, DeepSeek R1 a été entraîné sur une large palette d’entre eux, ce qui le rend polyvalent pour le code.
Des benchmarks montrent qu’il couvre au moins huit langages de programmation courants – notamment Python, Java, C++, C#, JavaScript, TypeScript, PHP et Bash – qu’il est capable de comprendre et de générer dans ses réponses.
Le dataset code inclut environ 87% de code pur pour 13% de langage naturel d’après certaines sources, afin de spécialiser le modèle sur la tâche de génération de code tout en conservant la compréhension du texte d’accompagnement.
En pratique, R1 peut donc lire ou produire du code dans ces différents langages, expliquer des extraits de code, corriger du code existant, etc., ce qui en fait un assistant précieux pour les développeurs multi-langages.
Cette combinaison de textes généraux, de données techniques spécialisées et de code fait de DeepSeek R1 un modèle très complet.
Il possède les connaissances encyclopédiques et linguistiques nécessaires pour les tâches de NLP classiques, tout en ayant absorbé suffisamment de connaissance du code et de problèmes techniques pour exceller dans les domaines du développement logiciel et des sciences.
Il est important de noter que l’entraînement de R1 a mis l’accent sur des problèmes bien définis et complexes (maths, programmation, logique), souvent via des données synthétiques et des compétitions, afin de maximiser ses facultés de raisonnement.
Cette orientation se reflète dans ses performances sur des benchmarks pointus et oriente les types d’applications pour lesquels il est particulièrement indiqué.
Capacités principales du modèle
DeepSeek R1 offre un large éventail de capacités fonctionnelles qui en font un outil versatile pour de nombreux cas d’usage en développement et en intelligence artificielle.
Ses créateurs soulignent que, bien qu’il puisse accomplir les tâches classiques des modèles de langage (génération de texte libre, Q/R, résumé, etc.), R1 se distingue surtout par ses performances sur les tâches nécessitant un raisonnement poussé. Voici un aperçu de ses principales capacités :
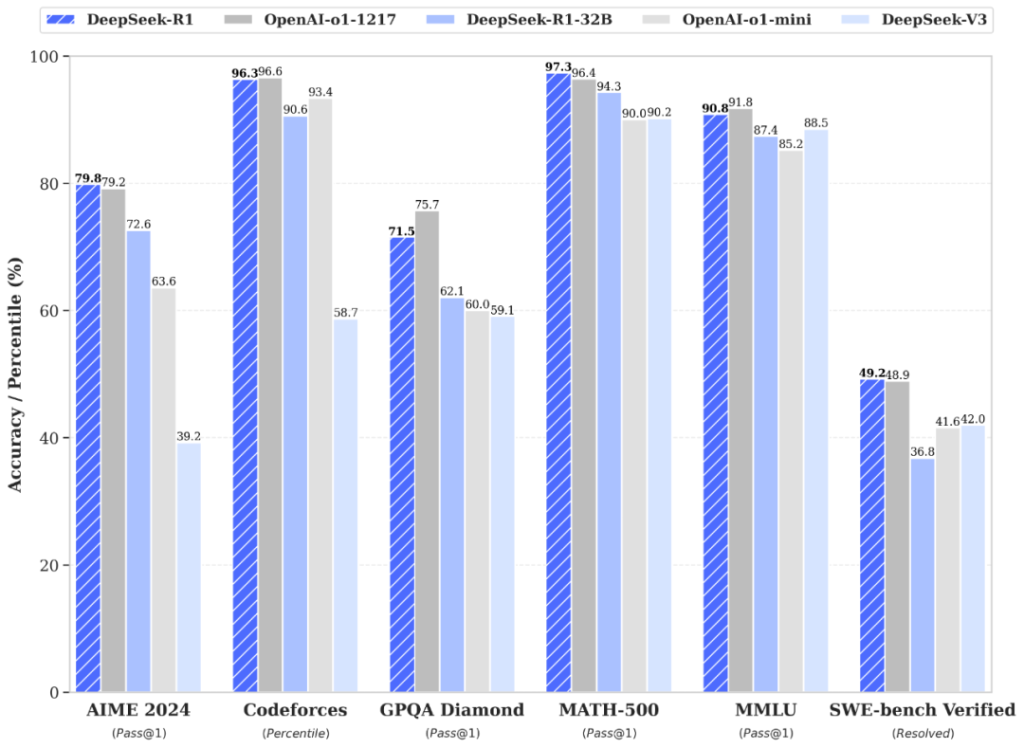
- Raisonnement logique avancé – R1 excelle dans les tâches de déduction, de résolution de problèmes complexes et de chain-of-thought approfondie. Il peut analyser étape par étape des problèmes compliqués et formuler un raisonnement structuré avant d’arriver à la conclusion. Par exemple, il est capable de résoudre des énigmes mathématiques de haut niveau, de planifier des solutions algorithmiques ou d’expliquer des concepts scientifiques ardus en détaillant chaque étape du raisonnement. Cette compétence se traduit par des scores remarquables sur des benchmarks de logique, de mathématiques et de science, où R1 rivalise avec les meilleurs en trouvant des solutions correctes et justifiées (il a par exemple atteint ~97% de réussite sur un test MATH avancé, indiquant sa maîtrise quasi-humaine en mathématiques complexes). En somme, dès qu’une tâche implique plusieurs étapes de réflexion ou une analyse critique, DeepSeek R1 démontre un haut pouvoir de réflexion et de vérification.
- Génération et compréhension de code – L’un des atouts majeurs de DeepSeek R1 est sa capacité en programmation. En tant que modèle entraîné sur de nombreux dépôts de code, il peut générer du code dans différents langages (Python, Java, C++, etc.), mais aussi expliquer, déboguer ou améliorer du code existant. Il peut servir d’assistant de codage intelligent en proposant du code conforme aux instructions, en identifiant les bugs dans un extrait donné ou en suggérant des optimisations. Sa compétence a été validée sur des évaluations de type HumanEval multi-langages et des concours de code : R1 se classe par exemple dans le ~96<
- sup>e</sup> percentile sur un benchmark de compétition Codeforces, indiquant un niveau expert en algorithmie. Concrètement, grâce à son immense fenêtre contextuelle, R1 peut avaler un dépôt entier ou un fichier volumineux et en ressortir une analyse complète. Par exemple, il est capable d’analyser l’intégralité d’une base de code pour y repérer des bugs, suggérer des corrections ou même générer de nouvelles fonctions cohérentes avec le style du projet. Peu de modèles peuvent en dire autant sans devoir morceler le code en morceaux (technique de RAG) – R1, lui, traite tout d’un bloc grâce à son contexte étendu. Pour les développeurs, cela signifie un gain de temps notable : vous pouvez lui présenter un module entier, il comprendra les dépendances globales et proposera du code ou des diagnostics en connaissance de cause.
- Compréhension de longs contextes et suivi de conversation – Avec ses 128k tokens de contexte, R1 est taillé pour les documents longs et les conversations prolongées. Il peut ingérer des rapports techniques volumineux, des logs applicatifs détaillés ou même un livre entier, puis en extraire l’information pertinente, en faire un résumé ou répondre à des questions fines portant sur des détails du document. Cette capacité à ne pas “oublier” le contexte sur de très longues distances le rend idéal pour des applications comme l’analyse de log (troubleshooting assisté par IA), la veille documentaire automatisée ou encore le support client sur de la documentation étendue. De même, dans un contexte conversationnel, R1 peut soutenir une discussion sur des dizaines de tours de dialogue tout en conservant une cohérence et en se souvenant des échanges précédents. Les problèmes de “perte d’information en cours de route” sont grandement réduits, ce qui améliore la qualité des réponses sur les chats longs ou les tâches multi-turns complexes. En somme, R1 maîtrise le fil contextuel là où beaucoup d’autres LLM décrochent au bout de quelques pages.
- Tâches de NLP généralistes – Bien que focalisé sur le raisonnement, DeepSeek R1 reste performant sur les tâches classiques du traitement du langage naturel. Il peut produire du texte créatif (rédiger des histoires, des articles courts, du contenu marketing), répondre à des questions générales en s’appuyant sur ses connaissances générales vastes, effectuer des résumés de texte, traduire sommairement d’une langue à l’autre, ou encore faire de la réécriture et correction grammaticale. Ces capacités plus conventionnelles ont été renforcées via des données de fine-tuning additionnelles pour que R1 soit utile au quotidien et pas seulement sur des problèmes académiques. D’après DeepSeek, le modèle est compétent en rédaction créative, en réponse à des questions factuelles ou encore en relecture/révision de texte. Par exemple, il peut prendre un article technique et en produire un résumé vulgarisé, ou bien suggérer des améliorations de style dans un paragraphe. Il convient de noter que R1 étant aligné sur les préférences humaines dans sa phase finale d’entraînement, il tend à suivre les instructions données de manière fiable et à produire des textes cohérents et pertinents, même en dehors des seuls exercices de logique.
En résumé, les capacités principales de DeepSeek R1 peuvent se synthétiser ainsi : c’est un expert du raisonnement (math, logique, code, science) doublé d’un assistant polyvalent en génération de texte.
Sa large couverture linguistique (double culture anglo-chinoise) et sa compréhension du code en font un outil sans équivalent pour des développeurs souhaitant à la fois interroger du texte libre et manipuler du code source.
Sa fenêtre contextuelle géante lui donne une mémoire phénoménale, utile pour traiter des tâches d’analyse complexes sur de gros volumes de données non structurées.
Enfin, son statut open source et entraîné sur des données publiques en font un modèle transparent et ajustable, que l’on peut affiner pour des cas d’usage spécifiques si besoin.
Utilisation via interface web, en local ou via API
DeepSeek R1 est mis à disposition des utilisateurs et développeurs de plusieurs façons, offrant une grande flexibilité d’utilisation :
- Interface web (mode chat) – Le moyen le plus simple de tester DeepSeek R1 est de passer par son interface web officielle. DeepSeek propose un chatbot en ligne (accessible à l’adresse chat.deepseek.com) où R1 est disponible en tant que modèle de conversation. L’interface chat permet de dialoguer avec le modèle en langage naturel. Une option appelée « DeepThink » peut être activée afin de demander au modèle d’afficher sa réflexion intermédiaire (ses étapes de raisonnement) avant la réponse finale, ce qui est très instructif sur la façon dont R1 parvient à ses conclusions. Aucune installation n’est requise pour cet usage : il suffit de se rendre sur le site, et il est possible d’échanger avec R1 gratuitement. Cela permet aux développeurs d’expérimenter rapidement ses capacités en mode conversationnel, de évaluer la qualité de ses réponses ou de le comparer à d’autres IA, sans avoir à déployer d’infrastructure.
- Téléchargement et utilisation en local – Étant un projet open source, DeepSeek R1 est téléchargeable pour un usage local. Les poids du modèle (ainsi que ceux des versions distillées 1.5B–70B) sont hébergés sur Hugging Face Hub sous l’organization
deepseek-ai, et le code source complet est disponible sur le dépôt GitHub de DeepSeek. Un développeur peut donc utiliser DeepSeek R1 en local en récupérant ces poids et en les chargeant sur sa machine. Bien sûr, compte tenu de la taille du modèle complet, une machine équipée de multiples GPUs haut de gamme (au moins 8 GPU A100/H100 reliés) est nécessaire pour faire tourner les 671B paramètres de R1 avec des temps de réponse acceptables. En revanche, les modèles distillés plus petits peuvent, eux, tourner sur un seul GPU : par exemple, la version 7B peut s’exécuter sur une carte graphique 16 Go, la 32B sur deux cartes 24 Go, etc. DeepSeek fournit dans son repo des outils et recommandations pour l’inférence locale, car le modèle MoE n’est pas supporté nativement par HuggingFace Transformers pour l’instant. Il est conseillé d’utiliser des frameworks optimisés comme vLLM ou DeepSpeed pour charger R1. Par exemple, on peut lancer un serveur d’inférence pour la version 32B distillée avec une simple commande :vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768. De même, la communauté a intégré le modèle dans des solutions prêtes à l’emploi (container Docker, notebooks, etc.) facilitant son déploiement local. En résumé, l’usage local est tout à fait possible et gratuit, que ce soit pour bricoler un chatbot sur son PC (avec un modèle réduit) ou pour intégrer R1 dans un service backend sur une machine de production. - Intégration via API cloud – Pour les développeurs qui préfèrent une solution plug-and-play sans gérer les ressources GPU, DeepSeek propose également une API hébergée. La plateforme DeepSeek fournit une API REST compatible avec le format OpenAI (mêmes schémas de requêtes) où il suffit de spécifier le modèle
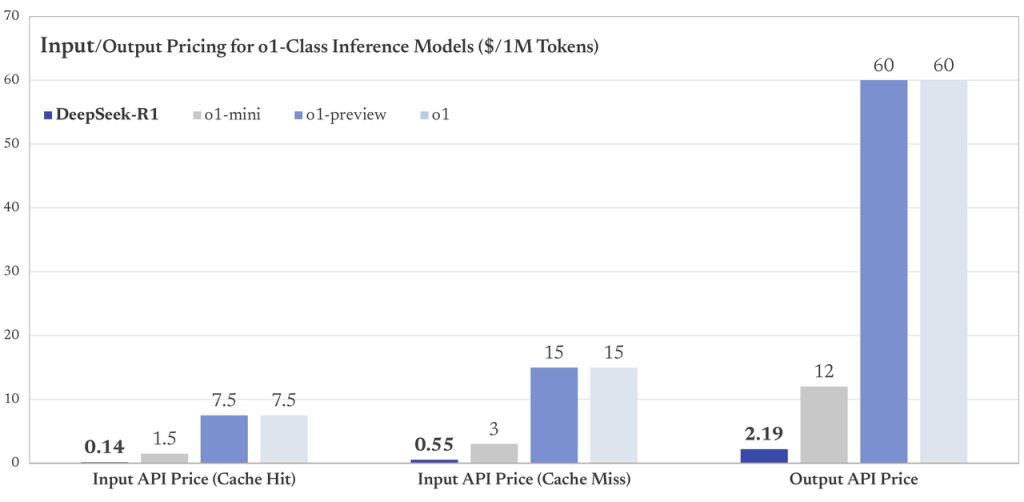
"deepseek-reasoner"pour utiliser R1 côté serveur. L’API cloud offre les atouts habituels (scalabilité, pas de gestion d’infrastructure) et est facturée à l’usage avec un tarif très compétitif par rapport aux APIs de modèles fermés. Au moment du lancement, le coût annoncé était d’environ 0,55$ par million de tokens générés, soit une fraction du prix des solutions commerciales équivalentes. Une clé API est nécessaire pour l’utiliser, obtenue en créant un compte sur la plateforme DeepSeek (certaines offres gratuites ou de test peuvent exister). L’API permet d’intégrer facilement R1 dans des applications : on peut par exemple l’appeler depuis un script Python pour obtenir une complétion de texte, l’inclure dans un chatbot sur son site web, ou l’utiliser dans un workflow d’entreprise, le tout sans se soucier des détails d’hébergement. Cette option “service web” est particulièrement intéressante pour tester rapidement R1 à l’échelle ou l’utiliser dans un produit sans retarder le développement (d’autant que le service était disponible dès le lancement du modèle).

En somme, DeepSeek R1 offre trois modes d’accès – en ligne via un chat web convivial, en local en exploitant l’open source, ou via une API cloud – ce qui permet à chaque développeur de choisir l’approche la mieux adaptée à son projet.
Ceux qui veulent juste explorer les réponses du modèle opteront pour l’interface web, ceux qui ont des contraintes de données (besoin de rester offline ou de personnaliser le modèle) préféreront le déploiement local, et ceux qui visent une intégration rapide dans un service pourront se tourner vers l’API hébergée.
Exemples concrets d’usage pour les développeurs
Grâce à ses caractéristiques, DeepSeek R1 ouvre la voie à de nombreux cas d’usage intéressants pour les développeurs et ingénieurs en IA. En voici quelques exemples concrets :
- Recherche d’information avec RAG : R1 peut être employé dans une solution de Retrieval-Augmented Generation où le modèle, couplé à une base de connaissances, fournit des réponses précises basées sur des documents. Par exemple, on peut bâtir un assistant Q/R technique pour une entreprise : on utilise R1 pour formuler des réponses détaillées, tout en extrayant au préalable les informations pertinentes depuis la documentation interne avec un moteur de recherche. La grande fenêtre de contexte de R1 lui permet d’ingérer de larges extraits de documentation récupérés, évitant un morcelage trop important. Le modèle excelle alors à synthétiser ces informations et à les présenter de manière cohérente à l’utilisateur, avec le raisonnement approprié. Un tel système peut servir de support utilisateur intelligent, répondant aux questions sur les produits de l’entreprise en combinant les connaissances internes (via RAG) et les capacités linguistiques de R1.
- Assistant de programmation IA : Avec ses compétences en génération de code et en débogage, DeepSeek R1 est un excellent candidat pour construire un assistant de développeur (AI pair programmer). Intégré dans un IDE ou un chatbot de support, il peut aider à générer automatiquement des segments de code à partir de descriptions en langage naturel, suggérer des corrections pour des erreurs de compilation, ou expliquer le fonctionnement d’un code existant. Par exemple, un plugin d’éditeur alimenté par R1 pourrait permettre à un développeur de demander : « Comment optimiser cette fonction Python ? » et R1 fournirait une version optimisée du code en expliquant ses modifications. De même, dans un contexte d’apprentissage, un étudiant peut coller un bout de code C buggué et demander à R1 de l’aider à trouver l’erreur – le modèle pointera la cause du bug et proposera un correctif, le tout avec une justification. Ces usages profitent de la compréhension profonde du code par R1 et de sa capacité à suivre des instructions complexes, ce qui augmente la productivité des développeurs.
- Agent conversationnel intelligent : R1 peut servir de cerveau à un assistant virtuel évolué capable d’interactions naturelles et de réalisations de tâches. Par exemple, on peut intégrer DeepSeek R1 dans un agent de support client automatisé : grâce à son alignement instructionnel, le modèle comprend les demandes des utilisateurs et y répond de manière pertinente, même si les questions nécessitent plusieurs étapes de réflexion ou la combinaison de plusieurs informations. On peut aussi imaginer un chatbot assisté par R1 pour de l’analyse de données – l’utilisateur converse avec le bot en langage naturel pour formuler des requêtes (ex: « Donne-moi les tendances de ventes ce mois-ci par région, et identifie les anomalies »), le bot utilise R1 pour interpréter la requête, éventuellement exécuter des formules ou du code en arrière-plan, puis renvoyer la réponse formatée. Dans ce rôle, R1 agit comme un intégrateur intelligent, capable de comprendre l’intention de l’utilisateur, de réaliser un raisonnement ou des calculs (il pourrait par exemple écrire une requête SQL ou du code Pandas via un outil externe), puis de formuler la conclusion en langage clair.
- Agents autonomes pilotés par l’IA : Grâce à son aptitude au raisonnement et à la planification, DeepSeek R1 peut être utilisé au cœur d’agents intelligents capables d’effectuer des enchaînements d’actions de manière autonome. Par exemple, on pourrait combiner R1 avec un framework type AutoGPT pour créer un agent qui reçoit un objectif global puis élabore lui-même ses sous-tâches, appelle des API/outils externes, et affine son plan jusqu’à atteindre l’objectif. R1 excellerait dans ce contexte en planifiant chaque étape avec méthode et en s’auto-évaluant en cours de route (grâce à son entraînement à la réflexion critique). Imaginons un agent DevOps : on demande à l’agent (propulsé par R1) de “mettre en place une infrastructure web scalable sur le cloud X”. L’agent va décomposer la tâche (créer un réseau, lancer des VM, configurer le firewall, déployer l’application, etc.), générer les scripts ou commandes nécessaires, les exécuter via des outils d’infrastructure, vérifier les retours, ajuster si besoin – tout cela en grande partie guidé par la capacité de R1 à raisonner sur l’état du système et les étapes suivantes. De tels agents autonomes, encore expérimentaux, bénéficient directement du haut niveau de raisonnement de R1, réduisant le risque qu’ils se bloquent ou commettent des erreurs de planification.
En plus de ces exemples, on peut citer bien d’autres usages envisageables : génération de contenus personnalisés (articles techniques, rapports) grâce au modèle de langage IA gratuit et open source qu’est R1, analyse intelligente de retours clients ou de tickets en langage naturel, assistant juridique capable de parcourir de longs contrats à la recherche de clauses spécifiques, etc.
La liberté offerte par la licence open source permet également aux développeurs d’affiner (fine-tuner) R1 sur des données spécialisées propres à un domaine : par exemple, créer une version de R1 particulièrement douée en biomédecine ou en finances en la ré-entraînant sur des corpus métiers (tout en respectant la licence des données utilisées).
En résumé, DeepSeek R1, de par sa puissance et son ouverture, peut être le moteur IA derrière une multitude d’applications innovantes – que ce soit pour enrichir des logiciels existants d’une intelligence conversationnelle, ou pour bâtir de nouveaux outils “AI-first” exploitant son remarquable sens raisonné.
Guide rapide : héberger localement ou utiliser via Hugging Face/GitHub
Pour les développeurs souhaitant héberger DeepSeek R1 en local ou l’intégrer dans leur environnement de travail, voici un guide rapide des étapes à suivre :
Obtenir les poids du modèle – Rendez-vous sur le Hub Hugging Face dans le dépôt deepseek-ai/DeepSeek-R1 (ou l’une des variantes distillées comme DeepSeek-R1-Distill-Qwen-7B). Vous y trouverez les fichiers de poids au format safetensors, accompagnés du code de configuration.
Téléchargez le modèle de votre choix. Assurez-vous d’avoir suffisamment d’espace disque (les poids 32B et 70B peuvent peser des dizaines de Go, le 671B complet est extrêmement volumineux et peut nécessiter un stockage spécialisé).
Alternativement, vous pouvez cloner le dépôt GitHub DeepSeek R1 de l’organisation deepseek-ai, où des scripts utilitaires de téléchargement sont fournis.
Préparer l’environnement – Il vous faut un environnement Python compatible avec les frameworks d’inférence pour LLM. Installez par exemple transformers (>=4.33) et accelerate, ainsi que vllm ou deepspeed si vous comptez utiliser ces optimiseurs. Notez que le modèle R1 complet est un MoE non standard, non pris en charge nativement par Transformers pour le moment. L’équipe DeepSeek recommande d’utiliser leur implémentation custom ou des solutions comme vLLM qui gèrent les architectures MoE efficacement. Assurez-vous de disposer du matériel requis : pour les petits modèles (jusqu’à 7B ou 14B), un seul GPU moderne (16–24 Go VRAM) suffit. Pour les modèles 32B et au-delà, prévoyez plusieurs GPUs en parallèle (ou une instance GPU multi-A100/H100) et configurez le tensor parallelism en conséquence. Par exemple, pour le 32B, deux GPUs 24 Go en parallèle peuvent convenir (d’où l’option --tensor-parallel-size 2 dans vLLM). Veillez à utiliser des précisions mixtes (BF16) pour réduire la consommation mémoire si possible, et activez éventuellement le paged attention ou le streaming si supporté par votre framework pour les contextes très longs.
Lancer le modèle – Une fois l’environnement prêt, vous pouvez charger et utiliser DeepSeek R1. Pour les versions distillées (compatibles architectures Qwen/Llama classiques), vous pouvez utiliser directement la pipeline Hugging Face, par exemple :
from transformers import AutoModelForCausalLM, AutoTokenizer
tok = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Qwen-7B", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Qwen-7B", device_map="auto", torch_dtype="auto")
out = model.generate(**tok("Votre question ici", return_tensors="pt").to(model.device))
print(tok.decode(out[0]))Pour le modèle complet MoE, il faut utiliser la solution fournie par DeepSeek (via leur repo DeepSeek-V3) ou un serveur vLLM. Par exemple, la commande suivante va démarrer une API locale pour R1-32B :
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B \
--tensor-parallel-size 2 --max-model-len 32768(Cette commande est tirée des instructions officielles et lance un endpoint REST local auquel vous pouvez ensuite faire des requêtes HTTP pour obtenir des réponses du modèle.) Une fois le serveur ou le modèle chargé, vous pouvez interagir avec R1 en lui envoyant des prompts.
Veillez à formater la requête selon le format attendu (généralement, R1 comprend une conversation sous forme User: … Assistant: …). Si vous utilisez directement la génération via Transformers, utilisez la méthode generate avec les bons paramètres de décodage (voir section Bonnes pratiques ci-après).
Intégration et tests – Vous pouvez maintenant intégrer DeepSeek R1 à votre application. Testez-le d’abord avec des prompts simples pour valider le fonctionnement.
Surveillez la consommation mémoire et temps de réponse, et ajustez les paramètres (par exemple, diminuer la longueur max générée, ou charger le modèle en 8-bit) selon vos contraintes. Si vous constatez que le modèle est trop lent ou lourd, envisagez d’utiliser une version distillée plus petite.
Enfin, n’hésitez pas à consulter la documentation du dépôt GitHub de DeepSeek R1 ainsi que la communauté Hugging Face pour des astuces de déploiement (quantification, optimisation GPU, etc.).
En suivant ces étapes, utiliser DeepSeek R1 en local devient tout à fait réalisable, que ce soit pour un simple proof-of-concept sur votre PC ou pour une intégration à grande échelle sur votre infrastructure.
Bonnes pratiques pour interroger le modèle efficacement
Interagir avec un modèle comme DeepSeek R1 nécessite d’adopter certains réflexes afin d’obtenir des résultats optimaux. Voici quelques bonnes pratiques de prompting et de configuration, spécialement adaptées à R1, qui vous aideront à exploiter tout son potentiel :
- Préciser clairement l’instruction dans le prompt – DeepSeek R1 a été entraîné en mode conversation (format utilisateur/assistant). Il n’est généralement pas nécessaire d’ajouter un system prompt ou un long contexte d’instructions sur le style de réponse ; au contraire, les concepteurs recommandent de fournir directement la consigne dans le message utilisateur pour éviter de perturber le modèle. Commencez donc votre prompt en vous adressant au modèle (ex: « Explique en détail… », « Donne-moi le code pour… »). Soyez explicite sur ce que vous attendez. Par ailleurs, pour garder les réponses cohérentes, limitez la température de génération à une valeur modérée (typiquement entre 0.5 et 0.7). Une température ≈0.6 est conseillée par DeepSeek pour R1, car cela évite autant les répétitions infinies que les réponses trop aléatoires. En somme : un prompt bien formulé, direct, et des paramètres de décodage raisonnables (température, top-p) vous garantiront les outputs les plus pertinents.
- Encourager le raisonnement étape par étape – Étant donné que R1 a une capacité intrinsèque à “penser à voix haute”, il peut être utile de lui demander de dérouler son raisonnement, notamment pour les problèmes complexes. Formulez vos questions de manière à inviter une solution détaillée. Par exemple, au lieu de « Quelle est la solution de ce problème de maths ? », préférez « Peux-tu raisonner étape par étape pour résoudre ce problème, et donner la réponse finale à la fin ? ». Pour les calculs mathématiques, les créateurs suggèrent d’inclure une directive du style : « Merci de détailler votre raisonnement pas à pas, puis d’indiquer la réponse finale entre \boxed{} ». Cela incite le modèle à appliquer sa puissante fonction de Chain-of-Thought et souvent à éviter les erreurs. De même, pour du code, vous pouvez lui demander d’expliquer son script avant de le donner. En guidant R1 ainsi, vous obtiendrez non seulement la solution, mais aussi la justification ou la démarche, ce qui est précieux pour valider la réponse. Par ailleurs, gérez bien le contexte fourni : R1 pouvant lire beaucoup d’informations, assurez-vous que les éléments que vous lui donnez en entrée sont pertinents et triés par importance. Évitez de saturer inutilement le contexte avec des données hors sujet, même si 128k tokens offrent de la marge. Un prompt focalisé sur les bonnes données amènera un meilleur résultat qu’un prompt fourre-tout.
- Tirer parti du mode “DeepThink” – DeepSeek R1 possède un mécanisme interne de réflexion (<think>) qu’il utilise avant de formuler sa réponse (<answer>). Normalement, il gère cela de lui-même lorsque c’est nécessaire. Cependant, il a été observé que dans certains cas, le modèle peut court-circuiter son propre raisonnement et répondre directement, ce qui peut nuire à la qualité sur des questions difficiles. Pour forcer R1 à pleinement utiliser ses capacités de réflexion, vous pouvez prédéfinir le format de sa réponse. Par exemple, dans l’interface officielle il existe un bouton “DeepThink” qui assure que le modèle commence toujours par son raisonnement. En utilisation API ou locale, vous pouvez reproduire cela en insérant au début du prompt de l’assistant un marqueur ou une consigne explicite du type : « <think>\n ». Les développeurs de R1 recommandent notamment de s’assurer que chaque réponse débute par la phase de réflexion (même cachée) pour maximiser la fiabilité des résultats. En pratique, cela peut se traduire par une petite astuce de prompt engineering – par exemple ajouter dans votre prompt utilisateur « (Le système réfléchit 🙂 » ou tout autre stratagème pour que R1 entame une réflexion structurée avant d’annoncer la solution. Naturellement, si vous utilisez le modèle en mode déployé normal (sans afficher le <think>), il donnera directement la réponse finale à l’utilisateur. L’idée est surtout, lors de l’élaboration du prompt, de pousser R1 à utiliser son plein potentiel de raisonnement sous le capot.
- Formatage des réponses et contrôle du style – R1 suit généralement bien les instructions de format (grâce à son alignement via RLHF). N’hésitez pas à préciser le style ou le format de sortie désiré dans le prompt. Par exemple : « Réponds en JSON valide », « Fournis le code uniquement sans explication supplémentaire », ou « Évite les digressions et donne une réponse concise de 3 phrases ». Le modèle respectera ces contraintes dans la majorité des cas. Si vous générez du code, il est judicieux de mettre la balise Markdown « ` autour de votre requête ou de demander explicitement la balise dans la réponse pour délimiter le code produit. Pour des tâches de question-réponse factuelle, vous pouvez aussi demander à R1 de citer ses sources (si vous l’avez équipé de RAG par ex.), ou de donner la réponse sous forme de bullet points, etc. Plus votre prompt est explicite sur le format attendu, plus R1 sera à même de s’y conformer. Profitez également de la longueur de contexte : vous pouvez inclure des exemples de format dans le prompt (quelques shots de démonstration). R1 saura généralement imiter le style illustré.
- Gestion du contexte conversationnel – Si vous utilisez R1 dans un chatbot multi-tour, veillez à résumer ou épurer le contexte quand il devient trop long, même si 128k tokens offrent une grande latitude. Réutiliser systématiquement l’intégralité de l’historique pourrait diluer l’attention du modèle. Préférez éventuellement fournir un résumé des points clés précédents après un certain nombre d’échanges. En outre, soyez attentif aux éventuelles hallucinations : comme tout grand modèle, R1 peut inventer des détails s’il manque d’informations. Une bonne pratique est de lui fournir des faits concrets lorsque c’est possible (par ex. insérer un extrait de documentation dans le prompt plutôt que de lui laisser combler les trous). R1 saura exploiter ces données précises pour éviter de deviner. Enfin, n’hésitez pas à itérer sur vos prompts : si la réponse n’est pas satisfaisante, reformulez la question en donnant plus de contexte ou en orientant davantage le modèle, R1 s’améliorera avec un prompt mieux ciblé.
En appliquant ces bonnes pratiques, vous pourrez tirer le meilleur de DeepSeek R1. Résumez les consignes, encouragez sa réflexion, paramétrez correctement la génération, et le modèle vous fournira des réponses de haute qualité, pertinentes et souvent accompagnées d’explications utiles – un atout de taille pour un développeur exigeant.
Licence et droits d’usage
L’un des points forts de DeepSeek R1 est sa licence ouverte et permissive. Le modèle (ainsi que son code et les poids associés) est publié sous la licence MIT. Cela signifie concrètement que :
- Vous pouvez utiliser R1 librement, y compris dans des projets commerciaux, sans redevance ni restriction d’usage. Aucune inscription particulière n’est requise pour l’utiliser localement, et l’API proposée par DeepSeek est facultative (à des fins de commodité). Cette absence de barrière financière ou juridique ouvre la porte à une adoption large du modèle par les entreprises comme par les particuliers. DeepSeek R1 est ainsi un véritable modèle de langage IA gratuit et open source, à l’opposé de certaines IA propriétaires coûteuses ou limitées par des conditions strictes.
- Vous êtes autorisé à modifier, adapter, affiner le modèle à votre guise. La licence MIT permet explicitement la création d’œuvres dérivées. Les développeurs peuvent donc fine-tuner R1 sur leurs propres données, le combiner avec d’autres modèles, le quantifier, le distiller à nouveau, etc., sans avoir à demander d’autorisation. DeepSeek encourage d’ailleurs ces pratiques, comme en témoigne la sortie de leurs modèles distillés. Il est mentionné que R1 « supporte l’usage commercial et autorise toute modification ou travail dérivé, y compris la distillation pour entraîner d’autres LLM ». Vous avez ainsi toute latitude pour intégrer R1 dans vos produits ou vos recherches, voire l’utiliser comme base pour développer un nouveau modèle spécialisé.
- Transparence et contributions : étant open source, R1 permet aussi de consulter ses détails techniques (architecture, hyperparamètres, données de pré-entrainement dans la mesure du possible) et la communauté est libre d’y contribuer. On a par exemple vu naître de nombreux forks ou projets liés à R1 sur GitHub/HuggingFace – certains travaillant à l’optimiser, à le quantifier pour du matériel moins puissant, ou à tester ses limites. Cette dynamique communautaire est rendue possible par la licence libre. Si vous identifiez des problèmes ou des améliorations, vous pouvez participer via des issues ou pull requests sur le dépôt officiel.
Il convient de noter un point concernant les modèles distillés : ceux-ci sont dérivés de modèles open source tiers (Qwen 2.5 d’Alibaba pour les 1.5B/7B/14B/32B, et Llama 3.x de Meta pour les 8B/70B).
Ils héritent donc en partie des licences de ces bases (Apache 2.0 pour Qwen, et une licence spécifique Llama 3 pour les versions Llama).
Néanmoins, ces licences autorisent également l’utilisation commerciale libre (Apache 2.0 est permissive, la licence Llama 3 autorise la recherche et l’usage commercial sous conditions de responsabilité).
DeepSeek a clarifié que l’ensemble de son offre R1 est ouverte à la communauté sans restriction majeure, et que même les sorties de l’API peuvent être utilisées pour affiner d’autres modèles.
En somme, vous avez les mains libres pour utiliser DeepSeek R1 comme bon vous semble, que ce soit pour un projet open source, un service commercial, de la recherche académique ou des expérimentations privées.
Cette liberté d’usage, couplée aux performances élevées de R1, est un facteur clé de son attrait. Les développeurs ne sont plus obligés de faire appel à une API payante ou à un modèle fermé pour bénéficier d’un LLM de très haut niveau – ils peuvent héberger leur propre “ChatGPT-like” sans frais, ou intégrer l’intelligence de R1 dans leurs workflows existants, le tout en restant maîtres de leurs données et de la personnalisation.
DeepSeek R1 représente ainsi un jalon important vers des IA plus ouvertes et collaboratives dans le domaine du développement logiciel et de la recherche en IA. Ce modèle prouve qu’il est possible de concilier excellence technique et ouverture totale, pour le bénéfice de toute la communauté des développeurs.
En conclusion, DeepSeek R1 apparaît comme un atout de choix pour quiconque souhaite explorer ou bâtir des solutions d’IA avancées sans les contraintes des écosystèmes fermés.
En tant que LLM open source pour développeurs, il offre une combinaison rare : la puissance d’un modèle de pointe (raisonnement, code, long contexte) et la flexibilité d’un logiciel libre (coût nul, adaptabilité, transparence).
Que ce soit pour améliorer des applications existantes, expérimenter de nouvelles idées ou repousser les frontières de la recherche sur le raisonnement des IA, DeepSeek R1 fournit une base solide et performante.
Avec sa disponibilité immédiate et son évolutivité, il ne tient qu’aux ingénieurs de faire preuve de créativité pour l’utiliser au mieux.
🚀 DeepSeek R1 marque peut-être le début d’une nouvelle ère où les modèles de langage avancés – autrefois gardés derrière des API payantes – deviennent gratuitement accessibles à tous les développeurs, libérant l’innovation et l’adoption à grande échelle de l’IA dans nos projets quotidiens.


