
DeepSeek-V2 est un modèle de langage de grande taille (LLM) open source de dernière génération, conçu pour exceller dans les tâches de code et de langage naturel.
Développé par la startup IA DeepSeek en Chine et sorti en mai 2024, ce modèle a rapidement attiré l’attention des développeurs et ingénieurs IA du monde entier.
Il se distingue par sa puissance et son accessibilité, prouvant qu’il est possible d’atteindre des performances de pointe sans nécessiter des infrastructures coûteuses.
L’objectif de DeepSeek-V2 est d’offrir un assistant intelligent capable aussi bien de générer du code que de dialoguer de façon contextuelle, le tout dans un esprit open source encouragé par la communauté.
En tant que modèle open source 2025 de haut niveau, DeepSeek-V2 s’adresse particulièrement aux développeurs et ingénieurs qui souhaitent intégrer l’IA dans leurs projets.
Avec ses capacités avancées et sa licence permissive, il offre une alternative gratuite pour un usage commercial aux solutions propriétaires.
Dans cet article, nous allons explorer en détail la nature de DeepSeek-V2, son architecture technique innovante, son vaste corpus d’entraînement, ses différentes variantes (7B, 16B, 33B) et comment l’utiliser efficacement – localement, via des plateformes en ligne ou par API.
Nous aborderons également ses principaux cas d’usage pour les développeurs, quelques bonnes pratiques de prompt engineering pour en tirer le meilleur parti, ainsi que les informations sur sa licence open source.
Architecture technique de DeepSeek-V2
DeepSeek-V2 repose sur une architecture Transformer à la pointe, enrichie de deux innovations majeures pour l’efficacité : une architecture Mixture-of-Experts (MoE) et un mécanisme d’attention latente multi-tête (MLA).
Contrairement aux modèles transformers denses traditionnels qui activent tous leurs paramètres à chaque calcul, DeepSeek-V2 adopte une approche sparse via MoE : le modèle comprend de nombreux « experts » (sous-réseaux spécialisés) et n’active qu’un sous-ensemble d’entre eux pour chaque token traité.
Ainsi, bien que le modèle totalise 236 milliards de paramètres, seulement ~21 milliards de paramètres sont réellement actifs pour un token donné. Cette conception permet d’atteindre l’échelle d’un modèle géant tout en réduisant considérablement la charge de calcul et la mémoire nécessaires à l’inférence.
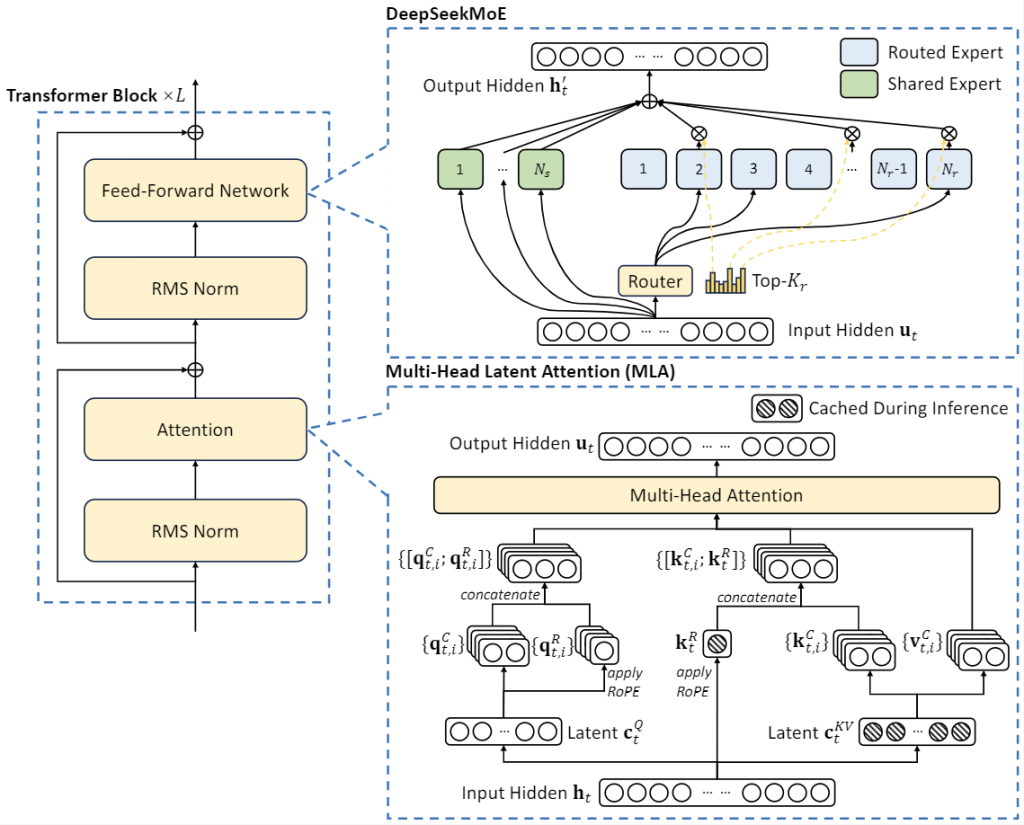
Le mécanisme MLA (Multi-Head Latent Attention) résout quant à lui un goulot d’étranglement classique des Transformers : le cache Key/Value qui explose en taille avec de longues séquences.
DeepSeek-V2 compresse ce cache KV dans un espace latent de plus petite dimension, ce qui réduit drastiquement les besoins en mémoire pour l’attention sans sacrifier les performances.
En pratique, ce mécanisme élimine la charge mémoire typiquement associée à la gestion de contextes étendus, permettant à DeepSeek-V2 de gérer des séquences très longues de manière fluide.
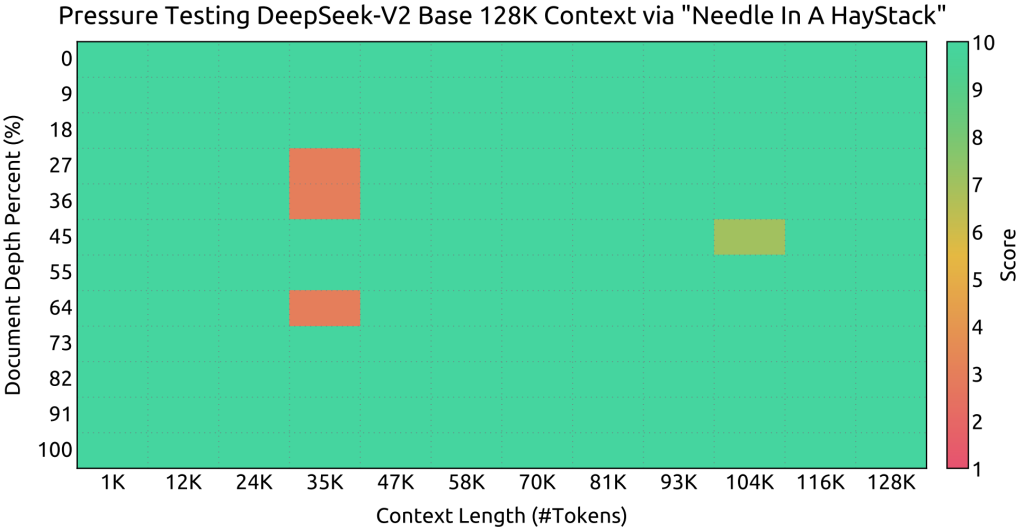
Le modèle prend nativement en charge un contexte étendu de 128 000 tokens (128K) – bien au-delà des LLM usuels – grâce à cette optimisation de l’attention combinée à une extension de positionnement Rotary (technique RoPE adaptée via l’extension YaRN).
Des tests internes “Needle In A Haystack” ont validé que le modèle peut maintenir une attention précise sur des documents immenses, en retrouvant des informations pertinentes même à des dizaines de milliers de tokens d’écart.
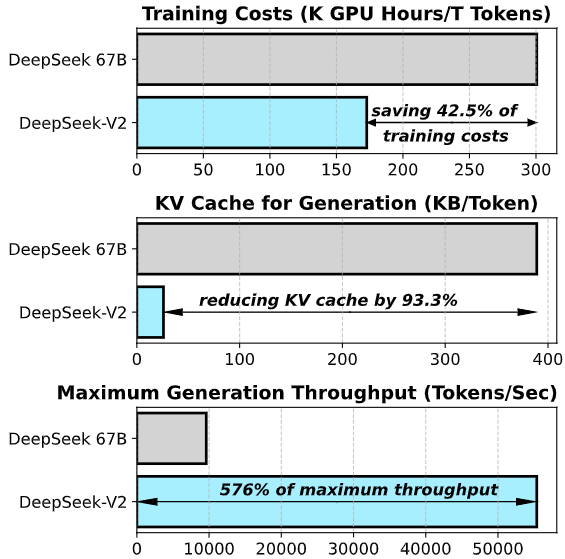
En résumé, l’architecture de DeepSeek-V2 allie la puissance d’un modèle géant (plus de 200 milliards de paramètres) à l’efficacité d’un modèle sparse.
Cette approche réduit d’environ 93% l’utilisation mémoire du cache d’attention par rapport à son prédécesseur dense de 67B paramètres, tout en multipliant par ~5,7 le débit de génération de texte.
Pour les développeurs, cela signifie que malgré sa taille massive, DeepSeek-V2 peut être déployé de façon plus économique en ressources qu’un LLM dense de taille équivalente.
De plus, le modèle utilise une précision Brain Floating Point 16 (BF16) optimisée et supporte l’inférence en FP16 ou 8-bit quantisé, ce qui améliore encore l’efficacité pratique sans perte majeure de qualité.
Corpus d’entraînement et objectifs
Pour acquérir ses vastes compétences, DeepSeek-V2 a été pré-entrainé sur un corpus massif d’environ 8,1 trillions de tokens couvrant des domaines et langues très divers.
Ce corpus inclut une grande variété de textes en langage naturel (articles web filtrés, littérature, données encyclopédiques, forums techniques, etc.) ainsi qu’une proportion significative de code source provenant de multiples dépôts publics.
L’équipe a porté une attention particulière à la qualité des données : les textes ont été filtrés pour éliminer les contenus indésirables ou de faible qualité, et une pondération a été effectuée pour équilibrer les langues.
En particulier, DeepSeek-V2 a reçu un accent bilingue anglais–chinois : le jeu de données contient environ 12% de tokens en chinois de plus qu’en anglais, afin de rendre le modèle très performant dans ces deux langues.
Naturellement, de nombreuses autres langues sont également présentes (le tokenizer BBPE du modèle comporte 100k tokens et a été optimisé pour le multilingue, y compris une bonne couverture du chinois et des caractères unicode).
Une part cruciale du corpus est constituée de données de code (extraits de dépôts GitHub, scripts, documentation de code, etc.), ce qui confère à DeepSeek-V2 une bonne compréhension de dizaines de langages de programmation dès le pré-entraînement.
Le modèle connaît ainsi aussi bien Python, Java, C++, JavaScript que des langages moins courants ou des syntaxes spécifiques (requêtes SQL, JSON, etc.).
Pour renforcer encore ces capacités techniques, les concepteurs ont continué l’entraînement du modèle sur un corpus additionnel de 6 trillions de tokens de code et de données mathématiques, produisant une variante spécialisée nommée DeepSeek-Coder V2.
Cette étape a fait passer le nombre de langages de programmation maîtrisés d’environ 86 à 338 langages supportés, couvrant pratiquement tout ce qu’un développeur pourrait utiliser.
À noter que DeepSeek-V2 de base reste un modèle texte seul (il ne traite pas directement les images), mais la société propose une branche multimodale séparée appelée DeepSeek-VL pour les entrées visuelles.
Ainsi, toute image ou schéma doit être converti en description textuelle (ou utiliser DeepSeek-VL2 en complément) pour être exploitée par DeepSeek.
Après cette longue phase de pré-entrainement non supervisé, DeepSeek-V2 a subi une optimisation supervisée et par renforcement pour affiner ses réponses.
D’abord, un Fine-Tuning Supervisé (SFT) sur ~1,5 million d’exemples de conversations multi-domaines a entraîné le modèle à suivre des instructions et à formuler des réponses utiles dans un format conversationnel.
Ces données comprenaient des dialogues sur le codage, les mathématiques, la rédaction, le debugging, etc., ce qui a appris au modèle à fournir des explications pas-à-pas, du contexte et à structurer ses réponses de manière pédagogique.
Ensuite, une passe de Renforcement via Feedback Humain (de type RLHF) a été effectuée en utilisant une méthode propriétaire appelée Group Relative Policy Optimization (GRPO). Ce processus a aligné DeepSeek-V2 sur des préférences humaines, améliorant la sécurité et la fiabilité de ses réponses.
Par exemple, le modèle a appris à éviter de proposer du code non sécurisé ou des solutions inappropriées, à refuser les requêtes hors-charte, et à adopter un ton aidant et poli.
Le fruit de ces ajustements est distribué sous la forme de DeepSeek-V2-Chat, variante orientée assistant (disponible en deux versions : l’une fine-tunée SFT et l’autre ayant subi en plus le RLHF).
Ces modèles conversationnels sont particulièrement adaptés pour créer des assistants de codage ou de support technique, car ils sont entraînés à gérer le dialogue multi-tour et à suivre fidèlement les consignes utilisateur.
Enfin, il convient de mentionner l’extension du contexte : initialement, le modèle pré-entraîné était limité à une fenêtre d’environ 4 000 tokens, mais les développeurs ont appliqué la méthode YaRN (Yet another RoPE extension) pour porter la fenêtre contextuelle à 128k tokens sans perte de cohérence.
Cela a nécessité de modifier les embeddings positionnels Rotary et d’entraîner le modèle à conserver le fil logique sur de très longues séquences.
En pratique, cela signifie que DeepSeek-V2 peut ingérer de très longues entrées (par exemple un fichier entier de code de plusieurs milliers de lignes, ou un document technique volumineux) en une seule requête, et s’en servir pour produire une réponse bien informée. Pour les développeurs manipulant de grandes bases de code ou des textes longs, c’est un atout considérable.
Capacités du modèle
Grâce à son architecture et à son entraînement approfondi, DeepSeek-V2 excelle dans de nombreux domaines clés pour les développeurs. Voici les principales capacités de ce modèle LLM open source :
- Génération et compréhension de code de haut niveau : DeepSeek-V2 est particulièrement doué pour écrire, compléter et améliorer du code. Sur des benchmarks de programmation tels que HumanEval, il obtient des scores Pass@1 comparables à ceux des meilleurs modèles du marché, démontrant sa capacité à produire du code fonctionnel du premier coup. Il peut générer des extraits de code complets à partir d’une description (par ex. « Écris une fonction Python pour trier une liste par ordre croissant »), compléter des fonctions partiellement écrites, ou même refactorer du code existant pour le rendre plus clair ou performant. Son entraînement intensif sur du code lui a apporté la connaissance de nombreuses bibliothèques et API courantes, ce qui lui permet souvent de proposer des solutions prêtes à l’emploi. De plus, DeepSeek-V2 comprend plus de 300 langages de programmation différents grâce à la variante coder, et peut naviguer aisément entre plusieurs langages dans un même contexte (par exemple analyser un extrait SQL puis passer à un script Python lié). Cela en fait un allié précieux pour accélérer le développement logiciel : il peut générer du boilerplate rapidement, traduire du code d’un langage à un autre, ou encore suggérer des correctifs à des bugs.
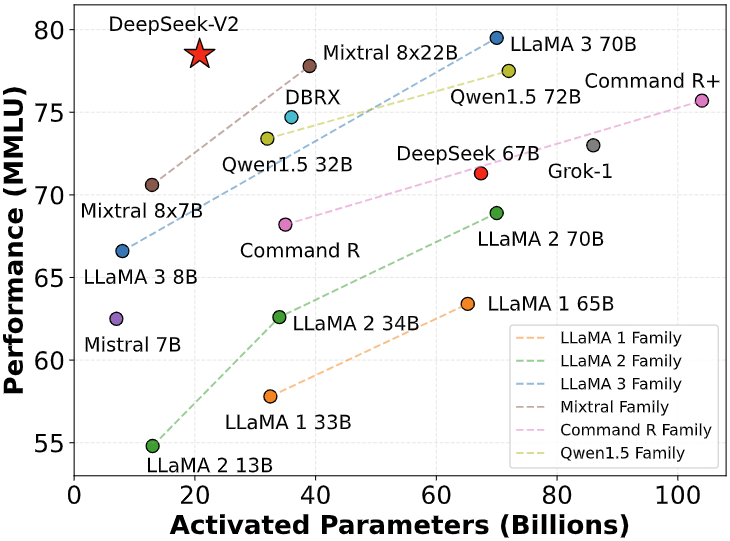
- Dialogue conversationnel et suivi d’instructions : En plus du code, DeepSeek-V2 possède une solide intelligence linguistique générale. Il figure parmi les meilleurs modèles open source aux benchmarks académiques de connaissance et de raisonnement (par ex. il atteint un niveau quasi-état-de-l’art sur MMLU, un test couvrant diverses connaissances). Concrètement, le modèle comprend des consignes complexes en langage naturel, peut analyser des problèmes logiques et fournir des explications détaillées. Pour un développeur, cela signifie que DeepSeek-V2 peut non seulement répondre à des questions techniques (« Qu’est-ce que le mécanisme OAuth2 et comment le configurer dans Spring Boot ? »), mais aussi résumer de la documentation, expliquer en français clair ce qu’un morceau de code accomplit, ou rédiger des notes techniques à partir de points clés. Son entraînement conversationnel lui permet de suivre un dialogue multi-tour : il garde en mémoire le contexte des échanges précédents et peut affiner ses réponses ou en poser de nouvelles questions pour clarifier la demande. Il a également été aligné pour être poli et factuel, évitant les digressions non désirées. On peut donc l’utiliser comme assistant virtuel dans un chat, en étant confiant qu’il respectera les instructions données et fournira des réponses utiles étape par étape.
- Compréhension de contexte long et mémoire étendue : Grâce à sa fenêtre de 128k tokens, DeepSeek-V2 peut gérer des entrées extrêmement longues tout en conservant le fil. Il peut par exemple analyser un ou plusieurs fichiers entiers de code ou de documentation fournis en contexte, puis répondre en tenant compte de tous ces détails. Cette capacité ouvre la porte à la RAG (Retrieval Augmented Generation) et à l’assistance sur de gros volumes d’informations. Par exemple, en combinaison avec un outil de recherche, DeepSeek-V2 peut ingérer les résultats trouvés et produire une réponse synthétique basée sur ces sources. On peut imaginer lui fournir un ensemble de documents techniques ou de tickets Jira pertinents, et lui demander ensuite une analyse ou un résumé global. En fait, il est possible d’intégrer DeepSeek-V2 dans des chaînes logicielles comme LangChain afin de le doter d’une mémoire externe ou d’outils complémentaires (recherche web, base de connaissances, exécution de calculs). Un agent IA construit de cette manière peut utiliser DeepSeek-V2 pour la partie raisonnement/rédaction tout en allant puiser des informations externes quand nécessaire – par exemple interroger une base documentaire interne, puis insérer les données trouvées dans sa réponse. En somme, la mémoire contextuelle élargie de DeepSeek-V2 lui permet non seulement de comprendre de longs prompts, mais aussi de servir de moteur de réponses intelligent sur de vastes corpus textuels.
- Polyglottisme et prise en charge technique multilingue : DeepSeek-V2 se démarque par ses performances en chinois bien supérieures à la plupart des modèles axés anglais. Son corpus bilingue et sa grande capacité lui donnent une excellente compréhension du mandarin (il surpasse même des modèles plus grands sur des benchmarks chinois comme C-Eval et CMMLU). Outre le chinois, il gère évidemment très bien l’anglais et dispose de compétences dans de nombreuses autres langues. Pour un développeur dans un environnement international, cela signifie qu’il peut aussi bien expliquer un algorithme en français qu’en anglais, commenter du code en espagnol ou documenter une API en chinois. De plus, comme mentionné, il connaît les conventions locales de multiples langages informatiques (noms de fonctions, bibliothèques propres à certains écosystèmes). Cette polyvalence linguistique en fait un atout pour des équipes multiculturelles ou pour développer des applications qui doivent comprendre et générer du texte en plusieurs langues.
DeepSeek-V2 offre ainsi un éventail de capacités très riche, allant de la génération de code avec IA jusqu’à la conversation contextuelle sur de larges bases de connaissances.
Dans les sections suivantes, nous verrons comment exploiter concrètement ces capacités via les différentes variantes du modèle et les outils de déploiement mis à disposition.
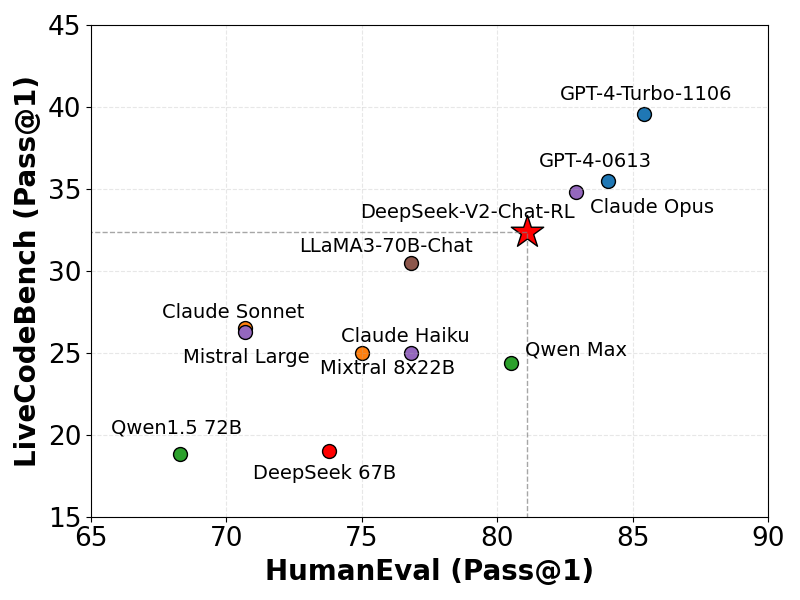
Variantes disponibles (7B, 16B, 33B) et configuration matérielle
La famille DeepSeek comprend plusieurs variantes de modèles pour s’adapter à différents cas d’usage et contraintes matérielles. En 2025, trois versions particulièrement notables pour les développeurs sont les modèles ~7 milliards, 16 milliards et 33 milliards de paramètres, aux côtés du modèle complet 236B. Voici un tour d’horizon de ces variantes et de leurs exigences :
- DeepSeek 7B : Il s’agit d’un plus petit modèle d’environ 7 milliards de paramètres (la version exacte fait ~6,7B) qui constituait une base dense de la première génération DeepSeek. Cette version allégée sert de point d’entrée pour des expérimentations légères ou des environnements à ressources très limitées. Bien qu’il n’intègre pas les améliorations MoE de V2, le 7B reste capable de compréhension de langage et de génération de code simples. Avantage : il peut tourner sur un seul GPU grand public (par ex. une carte 8–12 Go en 8 bits quantisés) ou même sur CPU pour des tests, avec une latence raisonnable. Limite : son contexte est restreint (quelques milliers de tokens) et ses performances, sans atteindre celles du V2 complet, suffisent seulement pour des tâches basiques ou du prototypage.
- DeepSeek-V2 Lite 16B : C’est une version allégée de DeepSeek-V2 basée sur l’architecture Mixture-of-Experts, totalisant 16 milliards de paramètres (2,4B actifs par token). Elle bénéficie de la plupart des avancées de V2 (y compris l’attention optimisée et un contexte étendu de 32k à 128k tokens selon la configuration) tout en étant bien plus facile à déployer. Usage : le modèle 16B offre un compromis idéal pour les développeurs souhaitant profiter de DeepSeek-V2 sur une machine locale. Il peut tourner sur une seule GPU haut de gamme – typiquement une carte de 24 Go VRAM suffit en demi-précision, et en le quantifiant en 4 bits on peut descendre autour de ~16 Go de VRAM nécessaires. Même sans GPU, il est possible de l’exécuter en mode CPU avec accélération partielle (au prix d’une lenteur significative). Performances : bien qu’un peu inférieures au modèle complet, la version 16B conserve d’excellentes capacités en génération de code et conversation grâce à son architecture MoE. Elle est idéale pour un usage personnel ou pour prototyper un service d’IA sur un serveur modeste, avant de passer éventuellement à plus grand.
- DeepSeek Coder 33B : Cette variante de ~33 milliards de paramètres fait partie de la série DeepSeek-Coder, spécialement entraînée pour les tâches de codage intensives. Le modèle 33B a été pré-entraîné sur un énorme corpus de 2 trillions de tokens majoritairement constitués de code (87% code, 13% langage naturel), ce qui en fait l’un des modèles de code open source les plus performants en 2025. Sa fenêtre contextuelle est d’environ 16k tokens, suffisante pour la plupart des fichiers source ou projets de taille moyenne. Usage : DeepSeek Coder 33B nécessite une configuration matérielle plus conséquente – idéalement deux GPU 24 Go (en le répartissant) ou une seule GPU très haute mémoire (40–80 Go) pour le charger entièrement en FP16. En pratique, beaucoup utilisent la quantization 4/8 bits pour faire tenir le modèle ~33B sur environ 20 Go de VRAM, ce qui le rend possible à exécuter sur une machine dual-GPU de gaming ou un serveur cloud standard. Performances : ce modèle offre une génération de code encore plus précise et fiable, surpassant la variante 16B sur les benchmarks comme HumanEval, MBPP ou MultiPL-E. Il se rapproche des performances des meilleurs modèles propriétaires dans le domaine du codage tout en restant libre d’utilisation. Pour un développeur, choisir le 33B peut être pertinent si l’objectif principal est d’avoir un assistant de programmation ultra-compétent ou de travailler sur des projets multi-fichiers où la plus haute précision est requise.
En plus de ces tailles clés, DeepSeek propose également le modèle complet 236B (DeepSeek-V2 Base) pour les cas où la performance maximale est recherchée.
Cependant, faire tourner 236B requiert une infrastructure lourde – typiquement 8 GPU de 80 Go selon les concepteurs – ce qui le réserve à des centres de calcul ou des déploiements cloud spécialisés. Pour la plupart des développeurs, les variantes plus petites (16B ou 33B) seront bien plus praticables au quotidien.
Enfin, il convient de mentionner que la famille s’est agrandie avec DeepSeek-V2.5, une version fusionnée sortie après V2 qui combine les atouts du modèle Chat et du modèle Coder en un seul ensemble de poids.
DeepSeek-V2.5 a reçu des ajustements supplémentaires d’alignement et constitue en quelque sorte la synthèse ultime de la génération 2.
Cependant, étant donné qu’il reste très proche de V2 en esprit (et également open source), on peut facilement passer à V2.5 le moment venu en changeant simplement de checkpoint.
Ce guide se concentre sur DeepSeek-V2, mais sachez que V2.5 est disponible et intègre les dernières améliorations sur la base de V2.
En résumé, DeepSeek offre une gamme de modèles LLM open source du plus léger au plus massif, permettant à chacun de trouver l’équilibre entre performance et contraintes matérielles.
Que vous disposiez d’un simple PC portable ou d’un serveur multi-GPU, il existe une variante de DeepSeek adaptée pour vous aider dans vos projets de développement.
Comment utiliser DeepSeek-V2
DeepSeek-V2 étant un projet ouvert, il peut être utilisé de plusieurs manières selon vos besoins et votre environnement de travail :
Interface web de chat interactive
La façon la plus simple de découvrir DeepSeek-V2 est de passer par son interface web de chat. DeepSeek AI propose un site web où le modèle est déployé derrière une interface de type chatbot (similaire à ChatGPT).
Vous pouvez y accéder pour converser avec le modèle sans avoir à installer quoi que ce soit localement. Par exemple, le site DeepSeek Chat (accessible via chat.deepseek.com) permet de tester la variante conversationnelle du modèle directement dans votre navigateur.
De même, une interface dédiée au modèle Coder existe (DeepSeek Coder Studio), conçue pour dialoguer autour de génération de code.
Ces plateformes offrent généralement un certain quota d’utilisation gratuit, ce qui est pratique pour essayer des requêtes variées (il peut y avoir une limite de tokens par mois ou un système d’API key gratuite).
L’interface web intègre souvent des fonctionnalités utiles : sélection du modèle (Chat vs Coder), réglages du style de réponse, historique des conversations, etc. Avantage : aucun besoin de GPU local, tout se passe sur le cloud de DeepSeek.
Inconvénient : les performances dépendent de la charge du service et vos données transitent par leurs serveurs (même si le modèle est open source, le service web peut être soumis à des conditions d’utilisation).
Téléchargement des poids et utilisation locale (Hugging Face)
Pour un usage plus libre et potentiellement hors-ligne, vous pouvez télécharger les poids du modèle et l’exécuter localement. Les checkpoints de DeepSeek-V2 (ainsi que de ses variantes Chat, Coder, etc.) sont disponibles sur Hugging Face Hub sous l’alias deepseek-ai.
Par exemple, on trouve les poids nommés DeepSeek-V2 (base), DeepSeek-V2-Chat (fine-tuné conversation), ou deepseek-coder-33b-instruct pour la version code 33B.
L’installation se fait via les bibliothèques Python standards : il suffit d’installer transformers (version récente) et d’utiliser la classe AutoModelForCausalLM pour charger le modèle. Un exemple minimal en Python :
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "deepseek-ai/DeepSeek-V2-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
Ce code va automatiquement télécharger le tokenizer et le modèle depuis Hugging Face (prévoir plusieurs dizaines de Go de stockage selon la version).
Le paramètre trust_remote_code=True est important car DeepSeek-V2 utilise du code personnalisé pour l’architecture MoE et l’attention MLA – en l’activant, Transformers récupère les modules Python fournis par l’équipe DeepSeek pour assurer le chargement correct du modèle.
Une fois chargé, vous pouvez interagir avec le modèle comme avec n’importe quel modèle causal : en lui fournissant un prompt textuel et en appelant model.generate() pour obtenir sa complétion ou sa réponse.
Conseil : par défaut, l’inférence via Hugging Face Transformers peut être moins optimisée que l’implémentation interne de DeepSeek, notamment à cause de la complexité MoE et du contexte géant.
Pour des usages intensifs (génération très longue ou requêtes nombreuses), envisagez des solutions optimisées comme vLLM, qui est un moteur d’inférence spécialisé supportant les architectures MoE et le streaming efficace de texte.
DeepSeek-AI a publié des patches pour intégrer ses optimisations dans vLLM, ce qui peut accélérer significativement le débit de génération sur GPU. Cependant, pour une utilisation interactive modérée ou des tests, l’approche standard avec Transformers fonctionne déjà bien.
Utilisation via l’API ou plateformes tierces
Si vous souhaitez intégrer DeepSeek-V2 dans une application sans héberger le modèle vous-même, vous pouvez passer par l’API fournie par DeepSeek ou par des services tiers.
DeepSeek propose son propre service API REST (avec une documentation sur api-docs.deepseek.com) permettant d’envoyer des requêtes au modèle hébergé sur leur infrastructure et de recevoir les réponses JSON.
Cela fonctionne typiquement via une clé API, avec une facturation possiblement basée sur le nombre de tokens.
L’API facilite l’intégration dans des applications web ou backend : par exemple, vous pouvez envoyer une requête contenant un prompt utilisateur, et récupérer la complétion du modèle pour l’afficher dans votre app.
L’avantage est de déléguer la charge computationnelle à DeepSeek – utile si vous n’avez pas le matériel requis localement. Côté tarifs, l’open source permet à DeepSeek de pratiquer des coûts faibles en comparaison des modèles fermés équivalents.
D’après les informations publiées, les coûts de l’API DeepSeek-V2 seraient de l’ordre de quelques centimes par million de tokens, ce qui est bien en dessous des tarifs de GPT-4 ou autres modèles propriétaires (ceci restant indicatif et susceptible d’évoluer).
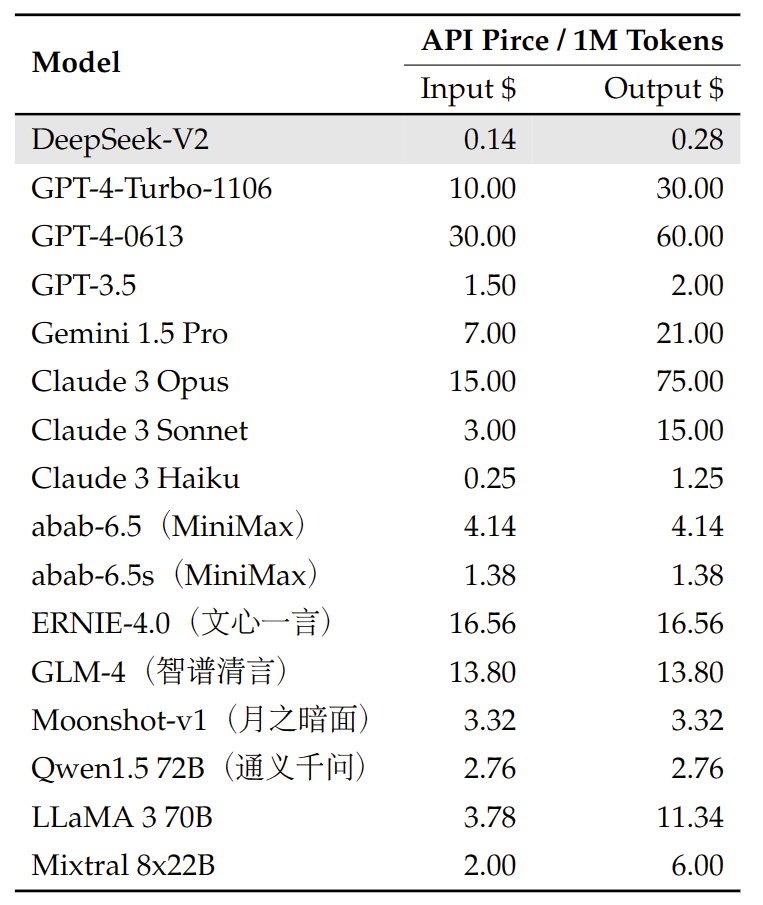
En dehors de l’API officielle, on retrouve parfois DeepSeek-V2 sur des plateformes ML tierces. Par exemple, HuggingFace Inference API vous permet de tester le modèle via une simple requête HTTP (sans charger localement) – bien que pour un usage prolongé, il faille souscrire à leur plan.
De même, des initiatives comme BytePlus ModelArk ont intégré DeepSeek (notamment les versions V3) pour le proposer sur leur cloud avec des crédits gratuits pour les tests. En résumé, si vous ne voulez ou ne pouvez pas gérer l’hébergement, il existe des moyens d’utiliser DeepSeek-V2 à distance via des services payants à la demande.
Guide d’installation local et déploiement
Installer et faire tourner DeepSeek-V2 localement est tout à fait possible pour un développeur, à condition de disposer du matériel adéquat et de suivre quelques bonnes pratiques :
- Pré-requis matériels : Pour la version complète 236B, il faut prévoir une machine extrêmement puissante (plusieurs GPU haut de gamme en parallèle). Par exemple, l’équipe DeepSeek mentionne avoir utilisé 8 GPU A100 de 80 Go pour héberger l’intégralité du modèle en mémoire. En BF16, le modèle entier occupe près de 200 Go de VRAM. Autant dire que peu de gens pourront le charger en entier localement. Heureusement, les variantes plus petites réduisent drastiquement ces besoins : le modèle 16B peut tenir sur une seule carte 24 Go (ou deux cartes de 12–16 Go en le répartissant), et le 33B sur deux cartes 24 Go. De plus, l’usage de la quantization est recommandé : en convertissant les poids en 8-bit ou 4-bit (via des librairies comme
bitsandbytes), on divise par 2 ou 4 la mémoire nécessaire au stockage des paramètres, avec un impact minime sur la qualité. Ainsi, un 16B quantifié 4-bit peut potentiellement tourner sur ~8 Go VRAM, et un 33B sur ~16 Go. Si vous ne disposez d’aucun GPU, il reste possible d’utiliser le CPU, mais l’inférence sera très lente (plusieurs secondes par token généré en général). Dans ce cas, privilégiez au moins un serveur avec de nombreux cœurs et beaucoup de RAM, et là encore utilisez des poids quantifiés pour tenir en mémoire. - Installation logicielle : Assurez-vous d’avoir Python 3.10+ et d’installer les dépendances nécessaires. Les principales bibliothèques incluent
transformers(version récente supportant MoE),torch(PyTorch, idéalement avec support CUDA si GPU disponible), et éventuellementaccelerateouvllmpour des optimisations. Si vous comptez quantifier, installezbitsandbytes. Un environnement virtuel est conseillé pour éviter les conflits. Ensuite, téléchargez le modèle comme montré précédemment (viaAutoModel.from_pretrained). Pensez à activerdevice_map="auto"pour un chargement automatique sur plusieurs GPUs si vous en avez plusieurs. Cela répartira les couches du modèle sur vos GPU de façon équilibrée. Pour le contexte 128k, notez que vous aurez besoin de versions optimisées de l’attention : la méthode YaRN utilisée par DeepSeek requiert des kernels spécifiques pour gérer autant de positions. Ces optimisations sont incluses dans le code du modèle (d’oùtrust_remote_code=Trueplus haut). En pratique, veillez à ce que la version de Transformers/PyTorch que vous utilisez prenne bien en charge l’attention RoPE étendue (sinon, de très longues séquences pourraient dégrader la précision). - Lancement et tests : Vous pouvez interagir avec le modèle via un simple script Python ou un Notebook Jupyter. Pour plus de commodité, de nombreux développeurs intègrent les modèles LLM dans des interfaces web locales. Par exemple, l’outil Oobabooga Text Generation Web UI est compatible avec DeepSeek-V2 et offre une interface type chat ou terminal pour l’utiliser. Il suffit généralement d’indiquer le chemin ou le nom du modèle Hugging Face, et l’UI se charge du reste (chargement, paramètres de génération, etc.). Cela permet d’obtenir chez soi une sorte de « ChatGPT local » personnalisable. N’hésitez pas à consulter la documentation communautaire ou le Discord de DeepSeek pour des guides d’installation pas-à-pas et des astuces de configuration.
- Performance et optimisation : Sur du matériel local, ajustez la longueur de contexte à vos besoins réels. Si vous n’avez pas 128k tokens de mémoire disponible, inutile d’essayer d’utiliser de si longues entrées. La plupart des usages se contentent de 4k, 8k ou 16k tokens de contexte, ce qui allégera d’autant la charge en mémoire et accélérera l’inférence. Vous pouvez aussi générer les réponses en streaming (par morceaux) pour réduire le pic mémoire. Pour des très gros déploiements, envisagez model parallelism manuel : par exemple charger certaines couches sur le CPU (offloading) et d’autres sur le GPU, ou répartir sur davantage de GPUs si disponible. Enfin, surveillez la température et les paramètres de génération – en contexte limité, DeepSeek-V2 est assez rapide, mais sur 100k tokens il peut ralentir, donc adapter top_k, top_p et utiliser sampling vs greedy peut aider à un bon compromis qualité/vitesse.
En respectant ces consignes, vous devriez pouvoir utiliser DeepSeek-V2 localement sans encombre, que ce soit pour un projet perso ou pour héberger un service interne. L’important est de bien calibrer le choix du modèle (taille) et les optimisations en fonction de votre hardware.
Beaucoup de développeurs témoignent que DeepSeek-V2, malgré sa taille, fait partie des modèles ultra-larges les plus rapides à générer du texte quand il est correctement configuré sur du matériel moderne.
Vous pouvez donc obtenir le meilleur des deux mondes : un contexte géant et une génération efficace, le tout sur votre propre machine.
Cas d’usage pour les développeurs
Les capacités de DeepSeek-V2 se traduisent par une multitude d’applications concrètes pour améliorer la productivité des développeurs et la qualité des projets logiciels. Voici quelques cas d’usages marquants où DeepSeek-V2 peut faire la différence :
- Assistant de codage intégré à l’IDE : L’un des usages les plus immédiats consiste à intégrer DeepSeek-V2 dans votre environnement de développement (IDE) en tant que pair programmer virtuel. Par exemple, via une extension Visual Studio Code ou JetBrains, le modèle peut fournir en temps réel des suggestions de complétion de code, documenter une fonction ou repérer des améliorations possibles dans votre fichier en cours d’édition. Imaginez que vous tapez une signature de fonction – DeepSeek-V2 pourrait suggérer automatiquement une implémentation complète. Ou bien vous sélectionnez un bloc de code compliqué, et il vous génère une explication en langage naturel de ce que fait ce code. Il peut également proposer des tests unitaires pour une fonction ou détecter des erreurs courantes. Tout cela, localement et en respectant la confidentialité de votre code (puisque le modèle peut tourner en interne, vos données ne sortent pas). Une telle intégration augmente la productivité et réduit les allers-retours constants vers la documentation ou StackOverflow, en apportant les connaissances du modèle directement dans l’éditeur.
- Génération de code sur demande par prompt : DeepSeek-V2 brille lorsqu’on lui fournit des consignes en langage naturel pour produire ou modifier du code. Plutôt que d’écrire manuellement des scripts verbeux, un développeur peut simplement décrire ce qu’il veut et laisser l’IA s’en charger. Par exemple : « Génère une fonction Python qui parcourt un fichier CSV et calcule des statistiques par colonne. » – le modèle va alors écrire la fonction correspondante en respectant les bonnes pratiques Python. De même, on peut lui présenter un extrait de code existant accompagné d’une instruction comme « Optimise cette fonction pour qu’elle s’exécute plus vite et explique tes changements ». DeepSeek-V2 retournera une version refactorée du code, suivie d’une explication en texte clair détaillant les optimisations apportées. Ce mode prompt → code s’utilise très bien via un notebook Jupyter ou un REPL : on écrit la demande en commentaire ou en chaîne de caractères, puis on obtient la sortie du modèle à intégrer. C’est un excellent moyen de générer rapidement des extraits répétitifs, d’obtenir une première ébauche pour un algorithme durant un coding challenge, ou même de produire du contenu technique (scripts de config, requêtes SQL complexes, patterns Regex, etc.) simplement en décrivant l’intention. Notons que DeepSeek-V2 a aussi été entraîné en fill-in-the-middle, ce qui signifie qu’il peut insérer du code manquant dans un fichier partiellement écrit : en donnant le contexte autour de la portion à compléter, il saura la remplir de manière cohérente. Cela permet par exemple d’automatiser l’ajout d’un bloc de code répété dans tous les fichiers d’un projet (ex: un en-tête de licence, ou un snippet d’instrumentation), en décrivant juste l’endroit où l’inclure.
- Chatbot technique et support aux développeurs : Grâce à son format conversationnel abouti, DeepSeek-V2 peut servir de moteur à un assistant virtuel type ChatOps ou support interne. Par exemple, une équipe de développement peut déployer un bot (sur Slack ou autre) alimenté par DeepSeek-V2-Chat pour répondre aux questions techniques des membres de l’équipe. Vous pourriez demander : « Comment configurer OAuth2 avec Spring Security ? » et le bot renverrait une explication détaillée avec éventuellement un extrait de configuration YAML ou Java en exemple. De même, coller un log d’erreur ou une trace de stack dans le chat et demander « D’où peut venir ce bug ? » permettra au modèle d’analyser le message d’erreur, de le rattacher à des causes probables et de proposer des pistes de résolution. Ce type d’assistant peut aussi être alimenté avec la documentation interne de l’entreprise (via fine-tuning ou en fournissant les docs en contexte) pour donner des réponses sur mesure. L’avantage de DeepSeek-V2 par rapport à un bot cloud est que vous pouvez l’héberger en on-premise, y intégrer des informations confidentielles (votre codebase privée, vos données spécifiques) et obtenir un support 24/7 pour les développeurs, sans exposer vos données à l’extérieur. Sa capacité à suivre une discussion fait qu’il peut poser des questions de clarification si une demande est incomplète, ou se souvenir des détails fournis auparavant lors d’une session de debug en cours. C’est comme avoir un collègue senior toujours disponible pour relire du code, expliquer un concept ou donner un coup de main sur un incident.
- Outils internes et automatisation offline : Étant open source et déployable localement, DeepSeek-V2 peut être intégré en profondeur dans vos flux de travail DevOps ou outils internes. Par exemple, on pourrait créer un générateur de documentation qui parcourt le code de votre dépôt et, grâce au modèle, produit automatiquement des commentaires ou un guide d’utilisation pour chaque module. Ou encore un assistant de migration de code qui, lors du passage à une nouvelle version de framework, suggère les modifications à apporter dans tout le code (par ex, convertir du Python 2 en Python 3). Dans un pipeline CI/CD, on peut imaginer une étape où, avant la fusion d’une pull request, l’IA examine le diff pour repérer d’éventuels bugs, problèmes de style ou risques de sécurité, puis commente automatiquement sur le merge request avec ses retours. Tout cela peut fonctionner en local, sur vos serveurs, garantissant la latence faible et la confidentialité. Avec son contexte de 128k, DeepSeek-V2 peut avaler de gros volumes lors de ces analyses (par exemple, plusieurs fichiers en même temps pour évaluer l’impact d’un changement global). Enfin, on peut combiner le modèle avec des scripts de pilotage pour créer des agents autonomes : par exemple, un agent qui lit chaque matin les rapports de logs (fournis en input) et génère un résumé des anomalies principales, ou un outil en langage naturel pour déclencher des commandes DevOps (« Déploie la build de la veille en staging » -> le modèle interprète et exécute les commandes correspondantes via un script). Les possibilités sont vastes, et elles tirent parti du fait que DeepSeek-V2 est librement programmable et extensible par n’importe quel développeur, sans passer par un service cloud restreint.
En somme, DeepSeek-V2 peut intervenir à toutes les étapes du cycle de développement logiciel : de l’écriture du code (avec assistance en IDE ou génération à la demande) à la maintenance (documentation, debug) en passant par l’automatisation (CI/CD intelligent, agents autonomes).
Son ouverture et sa puissance permettent aux ingénieurs de construire des outils innovants qui améliorent la productivité et la fiabilité des projets.
Bonnes pratiques de prompt engineering avec DeepSeek-V2
Pour tirer le meilleur parti de DeepSeek-V2, il est utile d’appliquer quelques bonnes pratiques de prompt engineering adaptées à ce modèle :
- Utilisez le bon format de modèle (base vs chat) : DeepSeek-V2 existe en version “base” (pré-entraînement brut) et en versions “chat”/instruites (SFT, RLHF). Si vous souhaitez un comportement conversationnel, courtois et obéissant aux instructions, optez pour DeepSeek-V2-Chat qui a été affiné dans ce but. En revanche, la version base peut être préférée pour des tâches de génération libres ou créatives sans format de dialogue (mais elle pourra nécessiter des instructions plus détaillées puisque moins alignée par défaut). Conseil : avec la version Chat, pensez à inclure éventuellement un prompt système au début pour guider le ton ou le contexte (par ex. demander au modèle de se comporter en assistant Python expert). Avec la version base, soyez plus directif dans votre prompt utilisateur car elle n’a pas le bénéfice de l’entraînement instruction – vous pouvez par exemple donner un exemple de question-réponse dans le prompt pour l’orienter.
- Fournissez du contexte pertinent : Grâce à la grande fenêtre de DeepSeek-V2, n’hésitez pas à inclure toutes les informations utiles dans le prompt. Par exemple, si vous posez une question sur un bout de code ou un bug, incluez le code en question dans votre requête. Si vous sollicitez une amélioration d’une fonction, fournissez-lui la fonction originale. Le modèle peut absorber énormément de contexte, donc tirer parti de cette mémoire améliore significativement la qualité des réponses. Pour une question ouverte, vous pouvez aussi contextualiser avec une courte description de votre projet ou de ce que vous attendez. Ceci permet d’éviter les réponses génériques – le modèle adaptera sa solution aux détails fournis.
- Soyez explicite dans les instructions : Formulez clairement ce que vous attendez de la réponse. Par exemple, si vous voulez du code, précisez la langue ( « en Python » ), et éventuellement le format ( « réponds avec uniquement le code sans explication » ou au contraire « explique chaque étape dans des commentaires » ). DeepSeek-V2 suit bien les directives lorsqu’elles sont explicites, grâce à son entraînement RLHF qui le pousse à respecter la demande. Vous pouvez aussi demander un style particulier (codage défensif, code idiomatique, etc.) et le modèle s’y conformera généralement. En outre, pour des tâches complexes, il peut être utile de décomposer la demande en étapes : le modèle excelle dans le raisonnement pas-à-pas, donc vous pouvez lui dire « commence par expliquer la démarche, puis donne la solution ». Il produira alors une réponse structurée.
- Tirez parti des templates de conversation : Les variantes chat de DeepSeek-V2 utilisent un format de conversation avec rôles (par ex.
<|SYSTEM|>,<|USER|>,<|ASSISTANT|>ou autres tokens spéciaux définis dans le tokenizer) afin de délimiter les tours de dialogue. Lorsque vous utilisez l’API ou le modèle directement, suivez le format recommandé (souvent indiqué dans la fiche du modèle Hugging Face). Par exemple, encadrez le prompt utilisateur avec le bon indicateur de début de message utilisateur, etc. Le modèle a été entraîné avec ces marqueurs, donc les respecter améliore la cohérence des réponses. La documentation fournit généralement un gabarit de conversation prêt à l’emploi – en l’utilisant, vous assurez que le modèle détecte bien quelle partie est la consigne et quelle partie est sa réponse. - Utilisez des contraintes pour orienter les sorties : DeepSeek-V2 est verbeux par nature et tente d’être complet. Si vous désirez une réponse concise, spécifiez-le dans le prompt (ex: « Réponds en une phrase. »). Inversement, si vous voulez une liste ou un tableau, demandez-le explicitement. Vous pouvez aussi imposer des éléments que la réponse doit contenir ou éviter. Par exemple, « Donne la réponse sous forme de liste à puces. », ou « N’utilise pas de bibliothèques externes dans ton code de sortie. ». Le modèle respectera généralement ces consignes formatives. Dans le contexte du code, vous pouvez par exemple exiger « fournis toujours des docstrings dans les fonctions générées » ou « adopte le style PEP8 ». Ces petites touches de prompt engineering guideront DeepSeek-V2 à produire exactement le format souhaité.
- Vérifiez et affinez par itérations : Bien que puissant, le modèle peut parfois halluciner des détails incorrects ou manquer une partie de la question. Si la première réponse n’est pas satisfaisante, n’hésitez pas à poser une question de suivi ou à reformuler votre demande. Dans un chat multi-tour, DeepSeek-V2 est capable de revenir sur sa réponse et de la corriger quand on lui indique un problème. Par exemple : « Ta solution ne compile pas chez moi, peux-tu la corriger ? » incitera l’assistant à debugger son propre code. De même, si une explication semble confuse, demandez-lui « peux-tu détailler davantage l’étape X ? ». Ce modèle a été entraîné à être coopératif et à accepter la critique, il ne se vexera pas et ajustera volontiers sa réponse. Profitez-en pour raffiner progressivement la sortie jusqu’à ce qu’elle corresponde à vos attentes.
En appliquant ces conseils, vous exploiterez pleinement le potentiel de DeepSeek-V2 dans vos requêtes. Le prompt engineering est un art qui s’affine avec la pratique : expérimentez différents phrasés, longueurs de contexte, et vous trouverez vite la manière la plus efficace de dialoguer avec ce modèle.
Rappelez-vous que DeepSeek-V2 a été entraîné pour fournir de l’aide utile tout en évitant les écueils (comme les suggestions dangereuses ou offensantes), donc en restant courtois et précis dans vos demandes, vous obtiendrez en retour des réponses de grande qualité.
Licence et gratuité pour un usage commercial
L’un des atouts majeurs de DeepSeek-V2 est sa licence open source permissive, qui autorise l’usage commercial. Concrètement, le code source associé au modèle est publié sous licence MIT, et les poids du modèle sont fournis sous une licence propre à DeepSeek permettant leur utilisation dans des projets commerciaux sans redevance.
Cela signifie que les développeurs et entreprises peuvent intégrer DeepSeek-V2 dans leurs produits, services ou workflow internes gratuitement, à condition de respecter les termes de la licence (qui portent typiquement sur la responsabilité, l’attribution éventuelle et l’absence de garantie).
Contrairement à certains LLM récents dont la licence limite l’usage commercial, DeepSeek-V2 a été explicitement ouvert pour favoriser l’innovation et l’adoption la plus large possible.
Vous pouvez donc déployer un assistant IA basé sur DeepSeek-V2 dans votre application SaaS, l’utiliser pour alimenter un chatbot de support client, ou encore l’inclure dans un outil vendu à des clients, sans avoir à payer de frais de licence à DeepSeek.
Ceci s’inscrit dans la philosophie de la startup DeepSeek de promouvoir un écosystème IA ouvert et collaboratif. Naturellement, si vous distribuez les poids du modèle ou une version modifiée, il faudra accompagner le tout du texte de la licence DeepSeek (similairement à ce qu’on fait avec une licence Apache ou MIT).
En résumé, du point de vue licence et coût : DeepSeek-V2 est gratuit y compris en usage commercial, ce qui lève un frein important pour son adoption industrielle.
Les seules dépenses à prévoir sont celles liées à l’infrastructure (coût des GPU/serveurs pour faire tourner le modèle) ou éventuellement aux services cloud si vous passez par une API tierce.
Aucune redevance ni permission spéciale n’est requise de la part de l’éditeur, ce qui offre une grande liberté pour intégrer ce modèle LLM dans vos projets professionnels.
Assurez-vous simplement de bien prendre connaissance du texte de la Model License DeepSeek pour vous y conformer, puis profitez sereinement de la puissance de DeepSeek-V2 dans vos applications !
Conclusion : DeepSeek-V2 s’impose comme un LLM open source 2025 incontournable pour les développeurs, alliant performances de pointe (notamment en génération de code) et efficacité grâce à son architecture innovante.
Avec un éventail de variantes adaptables à différents matériels, une utilisation possible localement ou via le cloud, et une licence libre, il constitue un outil polyvalent et économique pour créer la prochaine génération d’applications pilotées par l’IA.
Que ce soit pour coder plus vite, dialoguer plus intelligemment ou automatiser des tâches complexes, DeepSeek-V2 offre un guide complet et un compagnon fiable pour les développeurs en quête d’innovation.
En adoptant les bonnes pratiques présentées dans ce guide, vous serez prêts à exploiter tout le potentiel de DeepSeek-V2 dans vos projets dès aujourd’hui.


